Deep Learning
Der Begriff deep learning wird verwendet, sobald mindestens zwei Schichten (hidden layer) zwischen Ein- und Ausgabeschicht eines neuronalen Netzwerkes vorhanden sind. In der Praxis
Die explizite Nutzung des Begriffs deep learning bzw. deep neural networks hat sich etabliert, da Netzwerke mit vielen verdeckten Schichten, auf bedeutend komplexere Problemstellungen angewandt werden können. Um diese Möglichkeiten optimal auszuschöpfen, haben sie allerdings hohe Hardware-Anforderungen bezüglich Speicher und Rechenleistung.

Für verschiedene Anwendungsfälle eignen sich unterschiedliche neural network Architekturen, folgend werden die bekanntesten beschrieben:
Convolutional Neural Network (CNN / ConvNet)
CNNs wurden explizit für Bildverarbeitung und Mustererkennung entwickelt, was einige Optimierungen der Architektur für eine möglichst effiziente Berechnung erfordert.
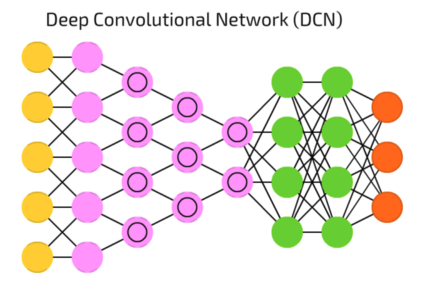 Vereinfachte Darstellung, Quelle: Fjodor van Veen, Asimov Institute
Vereinfachte Darstellung, Quelle: Fjodor van Veen, Asimov Institute
Da Bilddaten eine hohe Anzahl an Eingabeneuronen erfordern (Breite x Höhe x Anzahl Farbkanäle) kommt ein vollverbundenes (fully-connected) neurales Netzwerk, bei dem jeder layer die gleiche Anzahl an Neuronen besitzt, nicht in Frage. Die enorme Anzahl an Neuronen würde entweder extreme Rechenkapazitäten erfordern oder die Auflösung der Ausgangsbilder stark beschränken. Daher ist allen Ansätzen für ein CNN gemein, dass versucht wird die Anzahl Neuronen nach der initialen Input-Schicht durch Faltung (convolution) zu verringern. Nach einigen convolution Schichten, die definierte Muster in den Bilddaten erkennen und verstärken, folgen einige fully connected Schichten, welche die extrahierten Muster besser interpretieren können.
Convolution layer
Die convolution layer, in denen auf verschiedene Muster optimierte Filter auf die Bilddaten angewendet werden, sind die wichtigsten Bausteine von CNNs.
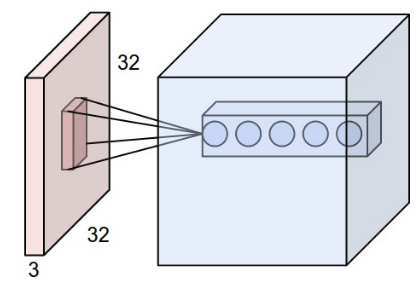 Quelle: [CS231N]
Quelle: [CS231N]
Wie in obigem Bild zu sehen wird eine Reihe von Filtern, die typischerweise eine größe von z.B. 5x5x3 (Höhe x Breite x Anzahl Farbkanäle) haben, auf die Bilddaten angewendet. Durch die Anwendung auf alle Bilddaten (der Filter wird über das Bild verschoben), entsteht ein zweidimensionaler Ergebnisvektor, der üblicherweise die Ursprungsgröße der Eingabe bezüglich Höhe/Breite beibehält. Durch die Anwendung mehrerer Filter wird insgesamt ein dreidimensionaler Ergebnisvektor erzeugt. Um die Datenmenge wieder zu reduzieren werden in regelmäßigen Abständen pooling layer eingefügt.
Pooling layer
Pooling layer werden vorallem benötigt um die Größe der Ergebnisvektoren, die nach mehreren convolution Schichten deutlich gewachsen sind, zu verkleinern und somit die Berechnungskomplexität wieder zu verringern.
 Quelle: [CS231N]
Quelle: [CS231N]
Wie in der Abbildung ersichtlich, handelt es sich bei pooling meistens um ein einfaches downsampling, also lediglich einer Reduzierung der Auflösung. Da die prägnanten Bestandteile eines Bilder, z.B. Kanten, Formen bereits durch die convolution Schichten verstärkt wurden, ist für eine weitere Verarbeitung nicht unbedingt die volle Auflösung erforderlich.
Im folgenden ist die Architektur eines kompletten CNNs für Gesichtserkennung ersichtlich, auffallend sind die pooling layer nach jedem convolution layer, sowie der eindimensionale Vektor auf der rechten Seite als Berechnungsergebnis.
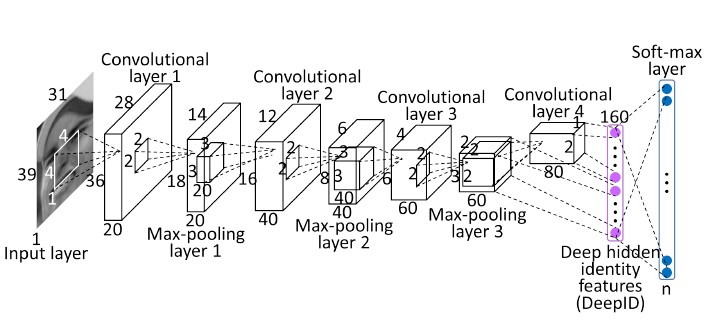 Quelle: [[SUN14]](#ref_sun14)
Quelle: [[SUN14]](#ref_sun14)Recurrent Neural Network (RNN)
 Quelle: Fjodor van Veen, Asimov Institute
Quelle: Fjodor van Veen, Asimov Institute
Im Gegensatz zu feed-forward Netzen, sind RNNs in der Lage, unmittelbar vorhergehende Entscheidungen zu speichern und in die Berechnung miteinzubeziehen. Dies bedeutet, dass ein trainiertes RNN Model sich nicht rein statisch verhält, sondern gänzlich neue Informationen kurzzeitig erinnern kann und daher flexibler ist. In dieser Hinsicht ähnelt das Netzwerk der menschlichen Neuronenaktivität. Daher finden RNNs vorallem Anwendung bei sequenziellen Datenströmen, dazu zählen beispielsweise Sensordaten, Spracherkennung oder Maschinenübersetzung.
Besonders bei Sprachverarbeitung (natural language processing) ist direkt ersichtlich, dass eine Einbeziehung vorangegangener Wörter bzgl. Grammatik und Satzstruktur anderen Ansätzen deutlich überlegen ist.
Quellen:
[CS231N]:Stanford University Course CS231n: Convolutional Neural Networks for Visual Recognition. URL: http://cs231n.github.io/convolutional-networks/
[SUN14]: Sun, Y., Wang, X., & Tang, X. (2014). Deep learning face representation from predicting 10,000 classes. URL: http://mmlab.ie.cuhk.edu.hk/pdf/YiSun_CVPR14.pdf