Microservices
Autor: Sebastian Janzen
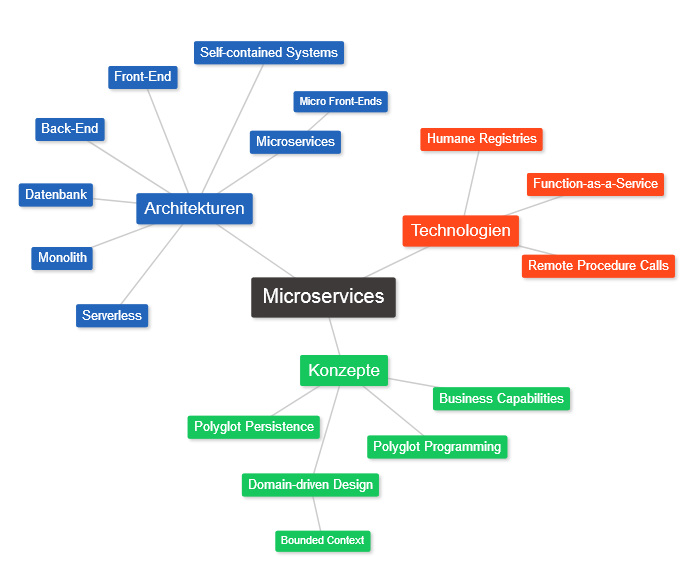
- Einführung
- Charakteristiken einer Microservice-Architektur
- Serverless
- Unterschiede zu monolithischen Anwendungen
- Abgrenzung zu Self-Contained Systems und Containern
- Microservices als Front-Ends
- Einsatz von Microservices
- Quellen
Einführung
Diese Mindmap soll einen Überblick darüber erschaffen, welche Themen in der Ausarbeitung angesprochen werden und wie sie anzuordnen sind.
Ein Microservice ist ein leichtgewichtiger autonomer Dienst, der eine einzige Aufgabe erfüllt und mit anderen ähnlichen Diensten über eine gut definierte Schnittstelle kollaboriert. Eine der Hauptaufgaben von Microservices ist eine Minimierung von Einflüssen im Falle einer möglichen Schnittstellenänderung. [NAMI14]
Monolithischen Anwendungen werden als ein Ganzes entwickelt. Die sogenannte Drei-Schichten-Architektur beinhaltet:
- Clientseitige Applikation
- Serverseitige Applikation
- Datenbank
Eine serverseitige Applikation ist ein solches Monolith, weil sie für HTTP-Anfragen zuständig ist, Zugriffe auf die Datenbank steuert und mit dem Browser interagiert. Eine Änderung im System führt zu einer neuen Version der ganzen Software. Die ganze Logik konzentriert sich in einer ausführbaren Datei. Es ist ein natürlich Weg zu entwickeln. Optimierung kan mithilfe eines Load Balancer erfolgen, damit mehrere Instanzen der Applikation nebenbei laufen können. Allerdings kann schwierig werden eine solche Anwendung auf Dauer zu entwickeln. Es erfordert viel Aufwand ständige Änderungen und Korrekturen zu implementieren, denn bei einem Monolith muss jedes Mal das ganze System neu erstellt werden. Desweiteren ist es aufwändig die Modularität der Software aufrecht zu erhalten, ohne das intern ungewollte Abhängigkeiten zwischen den Modulen entstehen. Auch eine Skalierung des ganzen Systems erfordert viel mehr Ressourcen, als eines einzelnen Moduls. [LEWI14]
Ein Vergleich einer monolithischen Anwendung in Microservices kann in der nächsten Abbildung betrachtet werden.
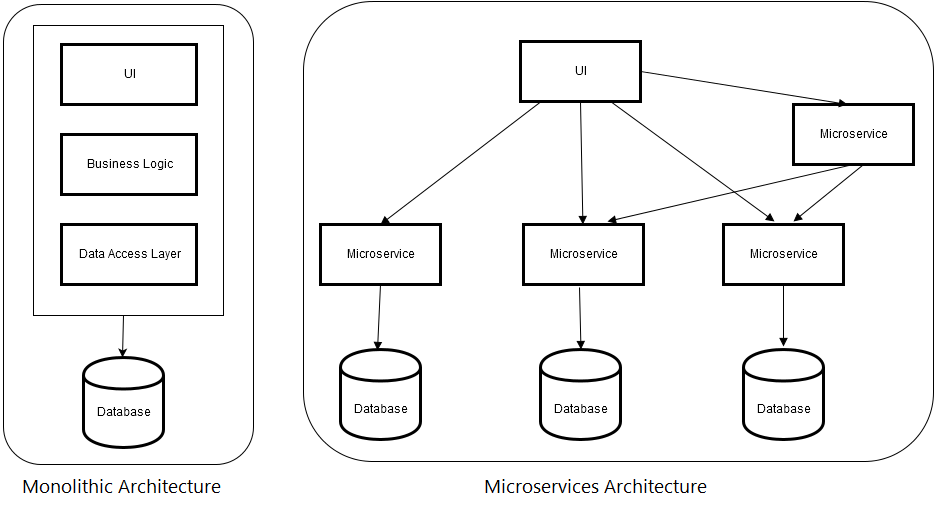
Microservices vs Monolith, Abbildung entnommen aus [TATV16]
Um die Nachteile von monolithischen Anwendungen zu umgehen, werden diese aufgeteilt in einzelne Dienste oder Services. Eine der weit verbreitenden Illustration der verschiedenen Ansätze der Partitionierung von Monolithen ist der Skalierungswürfel. Auf der horizontalen Ebene geht es um Skalierbarkeiteines Systems durch mehrere Instanzen einer Applikation. Diese können unter anderem hinter einem Load-Balancer laufen. Auf diese Weise wird versucht die Last umzuverteilen und konstante Antwortzeiten zu erzielen. Die Z-Achse der Skalierung würden mehrere Server eine identische Kopie an Code unterhalten. Hier unterhält jeder Server nur eine Untermenge der Daten. Auftretende Probleme wären Datenkonsistenz, Datenverteilung und Datenverfügbarkeit. Die X-Achse und die Z-Achse verbessern die Skalierbarkeit und Verfügbarkeit, jedoch auch die Komplexität des Systems. Um die Komplexität zu verringern wird auf der Y-Achse skaliert. Die Skalierung nach der Y-Achse setzt voraus, dass ein System logisch und physisch in funktionale Bereiche zerlegt werden kann. Dies kann zum höheren Kommunikationsaufwand führen, bringt aber mehr Flexibilität mit sich. [PIEN16], [NAMI14]
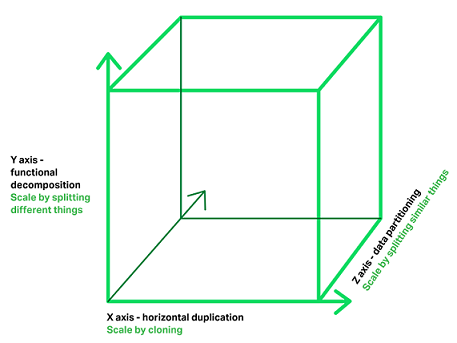
Skalierungswürfel, Abbildung entnommen aus [PIEN16]
Es gibt viele Entwurfsmuster, die zu Microservices verwandt sind. Die abgebildete monolithische Architektur ist als eine Alternative zu Microservices zu verstehen. Bei einer wachsenden Größe der Microservices, können diese schnell wieder sich zu kleineren Monolithen zusammensetzen. Die Muster werden nach folgenden Bereichen aufgeteilt:
- Kommunikation
- Datenhaltung
- Kern
- Stil
- Einsatzarten
- Sicherheit
Wobei es noch einige mehr sind. Im Laufe der Entwicklung werden Probleme auftauchen für welche diese Muster hilfreich sein werden.
Die Dienste werden nach Front-End und Back-End Services unterschieden. Je nach Client ergeben sich unterschiedliche Anforderungen an Granularität und Formate eines Service. Aus diesem Grund anstatt einer universellen Schnittstelle, sollten speziell entwickelte Lösungen für Nutzer angeboten werden. Ein API-Gateway ist eine Vermittlungskomponente welche benötigt wird, damit Services sich nicht direkt aufrufen können. Direkte Aufrufe können bei vielen Diensten die Kommunikationsstruktur schnell unübersichtlich und die Fehlersuche aufwändig machen. Außerdem erlauben lose Koppelungen zwischen den Microservices unabhängige Entwicklung, Einsatz und Skalierung. Das Gateway kann sich um Format- und Protokollumwandlung, Authentifizierung oder Überwachung kümmern. Um die angefordeten, am besten passenden Services zu finden stehen zwei Möglichkeiten zur Verfügung: clientseitig und serverseitig. Beide setzen voraus, dass die Dienste sich bei der Service-Registry an- und abmelden, auch in Fehlerfällen.
- Client-side discovery: Hier wird eine zentrale Service-Registry benötigt, für die Verwaltung von Diensten und deren Orten. Der Client braucht nur den entsprechenden Service aufzufordern und bekommt die nötigen Aufrufinformationen zurück. Die Dynamik, welche mit Microservices verbunden ist, macht die Automatisierung von diesem Prozess notwendig. Die Orte (Host, Port) der Microservices werden zur Laufzeit ermittelt und ändern sich nach Verfügabarkeit.
- Server-side discovery: Im Gegensatz zur vorherigen Lösung wird die Anfrage an einen Load-Balancer gestellt. Dieser fungiert als ein Router für den Service und kommuniziert mit einer Service-Registry. Der Code ist einfacher strukturiert verglichen mit den clientseitigem Fall, allerdings muss der Load Balancer ausfallsicher und skalierbar sein. Es kann eine cloudbasierte Lösung sein oder es wird eine Clusterlösung auf jeden Service-Host verwendet als lokalen Proxy. [RICH17], [PIEN16]
Auf alle Entwurfsmuster einzugehen würde den zeitlichen Rahmen um vielfaches sprengen, weswegen nur diese drei Muster beschrieben wurden.
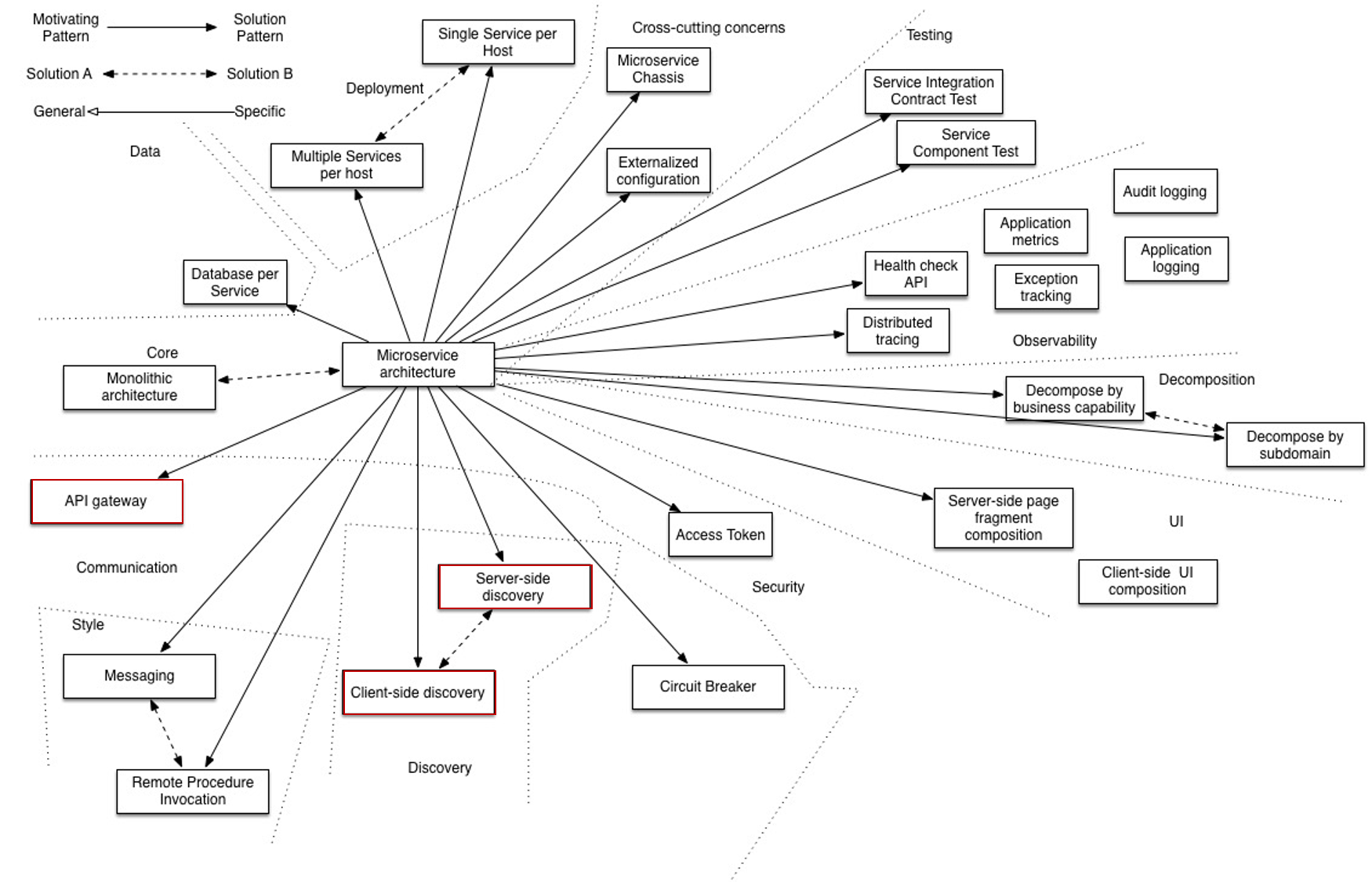
Verwandte Entwurfsmuster, Abbildung entnommen aus [RICH17]
Um einen gemeinsamen Datenbestand für alle Services und damit einen Engpass zu vermeiden, sollte Database-per-service-Muster zum Einsatz kommen - jeder Service verwaltet seine eigenen Daten. Es wird bewusst eine Datenredundanz in Kauf genommen. Dies erlaubt jedem Dienst eine eigene, für ihn geeignete Technologie zu wählen. [PIEN16] Die Abbildung Microservices Architektur zeigt einen möglichen Aufbau von Microservices. Jedem Dienst entspricht eine Funktionalität. Einige Dienste haben eigene Datenbanken, andere greifen auf eine gemeinsame Datenbank zu.
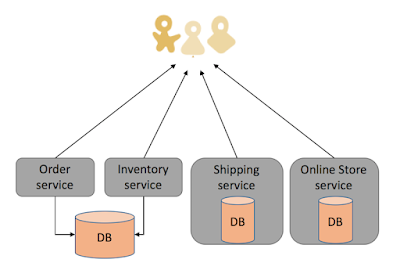
Microservices Architektur, Abbildung entnommen aus [MIRI17]
Charakteristiken einer Microservice-Architektur
Es gibt keine formale Definition dieses Architekturstils. Allerdings gibt es gemeinsame Charakteristiken, welche von vielen Microservices geteilt werden. [LEWI14]
Komponentisierung via Services
Normalerweise wird unter einem Komponenten der Teil einer Software verstanden, welches unabhängig von anderen veränderbar ist. Microservices bezeichnen einzelne Services, aber auch Bibliotheken, als Komponenten. Eine Bibliothek ist eine eingebundene Komponente und wird durch Funktionsaufrufe aus dem Speicher aufgerufen. Ein Service hingegen wird durch Remote Calls bzw. Web Requests aufgerufen. Der Vorteil eines Service gegenüber einer Bibliothek liegt in der Unabhängigkeit des Ersten. Ein einziger Prozess kann aus mehreren Bibliotheken bestehen und wäre eine davon verändert, müsste die gesamte Applikation neu aufgesetzt werden. Eine Aufteilung in Services wirkt dem entgegen, weil meistens nur der jeweilige Service geändert werden muss. Desweiteren bringt eine solche Aufsplittung sauber definierte Komponentenschnittstellen mit sich. Das bedeutet, dass einzelne Softwarekomponenten besser voneinander getrennt sind. [LEWI14]
Aufbau um Business Capabilities
Microservices sollten rund um die Business Capabilities der Organization aufgebaut werden. Business Capabilities definieren die wichtigsten Businessfunktionen. Sie beschreiben "was" ein Unternehmen macht. Denn das Gesetz von Conway besagt: Jede Organisation die ein System entwirft bekommt am Ende ein Entwurf welches die Kommunikationsstruktur der umzusetzenden Organisation nachbildet. Der Technologiestack deckt ein breites Feld von Software ab, wie GUI, Datenbanken, Schnittstellen. Das wiederum bedeutet, dass es cross-functional Entwicklerteam sein muss, um all die Bedingungen zu erfüllen. [LEWI14]
Die nächste Abbildung stellt dar, wie Microservices sich den Business Capabilities einer Organisation anpassen.
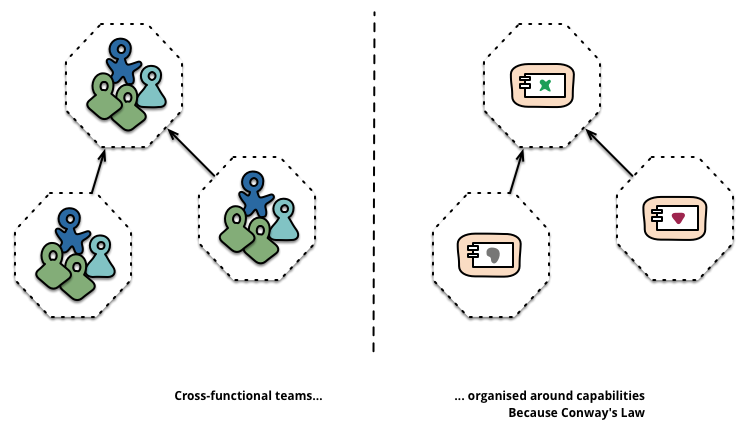
Microservices und Business Capabilities, Abbildung entnommen aus [LEWI14]
Service als Produkt
Software sollte nicht als ein Projekt, sonder vielmals als ein Produkt gesehen werden. Das bedeutet, dass ein Entwicklungsteam während des gesamten Lebenszyklus sich darum kümmert. Auf diese Weise hat dieses Team das Feedback für das Verhalten der Software in realen Arbeitsbedingungen und einen engeren Kontakt zu den Nutzern. Das kreiert eine engere Bindung an das eigene Produkt. Diese Mentalität geht Hand in Hand mit dem Einsatz von Business Capabilities. Eine Software wird nicht mehr als ein Bündel von Funktionalitäten zu betrachten, die fertiggestellt werden müssen, sondern es wird zu der Software eine andauernde Beziehung aufgebaut, um die Business Capability zu verbessern. [LEWI14]
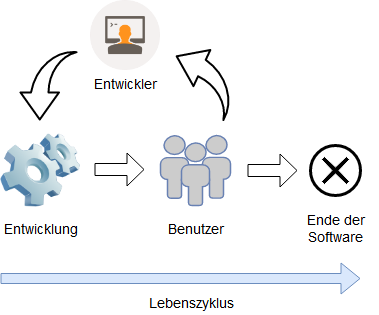
Betreuung während des Lebenslaufs, eigene Abbildung
Smart endpoints and dumb pipes
Die Applikationen der Microservices sollten abgekoppelt und zusammenhängend wie möglich sein: Empfangen einer Anfrage, Bearbeitung und senden einer Antwort. Die Protokolle sollten hingegen unkompliziert sein. Einer der meistgenutzten Protokolle ist HTTP. Das erlaubt die Infrastruktur des Webs zu nutzen, um Ressourcen zu sparen. Eine andere populäre Möglichkeit ist es den Lightweight Message Bus zu nutzen, wo die Infrastruktur nur als Router von Nachrichten fungiert (dumb pipes). [LEWI14]
Dezentralisierte Führung
Dezentralisierte Führung ist ein Konzept welches aus mehreren Ansätzen besteht. Eines davon erlaubt den einzelnen Entwicklerteams ihre Stärken in verschiedenen Technologien anzuwenden und zusammen ein leistungsfähiges Produkt zu entwickeln, anstatt ihnen einen technologischen Standard aufzuzwingen. Das heißt, dass unter anderem jeder einzelner Service in der dafür am besten passenden Programmiersprache geschrieben werden kann, aber nicht unbedingt muss. Diese Eigenschaft heißt Polyglot Programming. Die Entscheidung liegt auf der Ebene der Entwickler, was nicht bedeutet, dass es überhaupt keine Richtlinien gibt. Einen weiterer Ansatz der dezentralisierten Führung bringt die Amazons Herangehensweise zur Geltung: "You build it, you run it!". Damit ist gemeint, dass ein Entwicklungsteam nicht nur die eigentliche Entwicklung übernimmt, sondern auch die Installation, die Überwachung und die Steuerung dieses Produktes im Einsatz. Das geht weg von dem üblichen Konzept "Entwickeln und vergessen", wo nach der Entwicklung andere Bereiche sich um das Produkt kümmern. [LEWI14], [PECK17]
Dezentralisiertes Datenmanagement
Domain-driven Design (DDD) modelliert komplexe Systeme basierend auf Domänen; eine Domäne ist wiederum ein Einsatzbereich einer Software. Bounded Context ist ein Entwurfsmuster aus dem DDD. Es beschreibt eine Abgrenzung in der ein bestimmtes Modell definiert und verwendet wird. Es teilt komplexe Domänen in mehrere Kontextgrenzen und beschreibt die Beziehungen zwischen ihnen. Je nach Kontext variieren sich die Sichtweisen auf bestimmte Modelle: Modell Customer kann im Kontext von Sales vorkommen, aber nicht unbedingt bei Support. Das ist sowohl für Monolithen, als auch für Microservices nutzbar, wobei die letzteren eine natürliche Korrelation zu Bounded Context besitzen. Bounded Context verdeutlicht und verstärkt eine Trennung in verschiedene Kontextbereiche. [EVAN15], [FOWL14], [LEWI14]
Hier sind klar erkennbare Grenzen der Bereiche Sales und Support mit Berührungspunkten bei Customer und Product definiert.
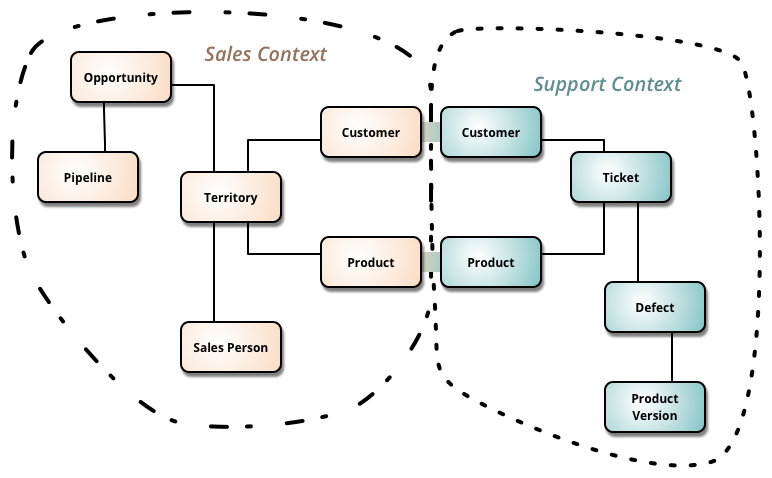
Bounded Context, Abbildung entnommen aus [FOWL14]
Die Dezentralisierung bei Microservices betrifft auch die Datenbanken. Es wird bevorzugt pro Service eine Datenbank zu haben, seien es nur unterschiedliche Datenbank-Instanzen oder komplett unterschiedliche Datenbanktechnologien. Eine der Probleme von dezentralisiertem Datenmanagement ist Update Management. Wenn im monolithischen Systemen Transaktionen für Updates genutzt werden, um Datenkonsistenz zu garantieren, kann es bei Microservices aufgrund von temporären Kupplung problematisch. Verteilte Transaktion sind sehr schwer umzusetzen, weswegen Microservices transaktionslose Koordination zwischen den Services einsetzen. Mögliche Probleme werden von kompensierenden Operationen abgefangen. [LEWI14]
Die nächste Abbildung vergleicht ein monolithisches System mit Microservices in Bezug auf die Datenbanken.
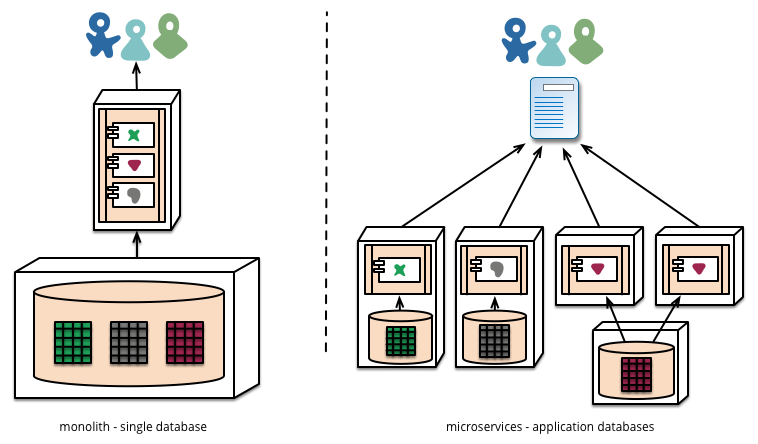
Dezentralisierte Datenbanken, Abbildung entnommen aus [LEWI14]
Infrastructure Automation
Testautomatisierung und Ansätze wie Continuous Integration und Continuous Delivery helfen bei der Entwicklung von stabiler und hochwertiger Software. Das illustriert das nächste Bild. [LEWI14]
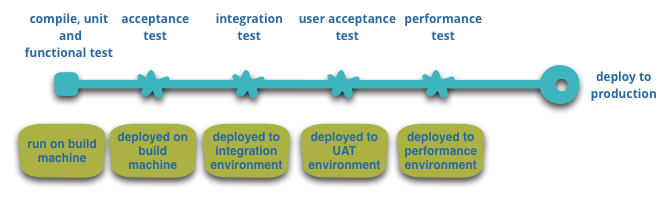
Basic Pipeline, Abbildung entnommen aus [LEWI14]
Design for failure
Ein Service ist nicht gegen Ausfälle und Fehler geschützt, deshalb sollte er immer gegen mögliche Fehlerfälle ausgiebig getestet werden. Verglichen mit einem monolithischen Design, fällt das bei Microservices komplexer aus, wodurch die Entwickler ständig beachten müssen wie es auf die Benutzbarkeit beim Nutzer auswirkt. Da allerdings nicht alle möglichen Probleme abgedeckt und vorhergesehen werden können, kommt Echtzeit-Monitoring zum Einsatz. So kann bei einem Ausfall direkt eingegriffen und ein Service wieder zum laufen gebracht werden. Relevanten Metriken und weitere wichtige Informationen über den Softwarestatus erlauben es rechtzeitig Fehler zu erkennen. [LEWI14]
Evolutionäres Design
Eine Software sollte so entworfen werden, dass statt es bei größeren Änderungen zu verwerfen, diese weiterentwickelt werden kann. Die wichtigsten Eigenschaften eines Komponenten sind Austauschbarkeit und Erweiterungsfähigkeit - wie kann eine Komponente überarbeitet werden, ohne dass andere Komponenten davon betroffen sind. Oftmals wird ein Service verworfen anstatt auf lange Sicht überarbeitet zu werden. Manchmal macht es Sinn mehrere Dienste zu gruppieren, falls diese immer wieder Abhängigkeiten während Änderungen zeigen. [LEWI14]
Client-Kommunikation mit Microservices
Direct Client-to-Microservice Communication
Jeder Microservice hat einen öffentliches Endpunkt. Um Information zu bekommen schickt ein Client Anfragen an jedes einzelne Service. Nachteile sind die vielen Anfragen, welche ein Client ausführen muss. Bei hunderten Diensten wäre es zu ineffizient die Anfragen über das öffentliche Internet zu verschicken. Mit einigen Protokollen ist es nicht performant über das Internet zu kommunizieren und außerhalb der Firewall sollte HTTP zum Einsatz kommen. Direct Calls machen es schwer die Microservices im Nachhinein zu restrukturieren, denn es kann vorkommen, dass zwei Dienste zusammengeführt werden sollen, aber der Client sie beide einzeln anspricht. Diese Ansatz wird aus diesen Gründen eher selten verwendet. [RICH15]

Direct Call, Abbildung angepasst aus [NAMI14]
API Gateway
Ein API Gateway ist ein Server mit einem Endpunkt für alle Anfragen des Clients. Je nach Client werden verschiedene APIs zur Verfügung gestellt. Zu den Aufgaben zählen unter anderem:
- Authentifizierung
- Monitoring
- Load Balancing
- Caching
- Anfragen-Management
- Protokoll-Umwandlung
- Anfragen-Routing
Ein API-Gateway leitet alle Anfragen zu den Microservices; es kann mehrere Dienste aufrufen und deren Ergebnisse sammeln; es führt Umwandlungen durch zwischen Webprotokollen und internen Dienst-Protokollen. [RICH15]

API Gateway, Abbildung angepasst aus [NAMI14]
Humane Registries
Humane Registry ist eine automatisierte Dokumentation für Microservices, designt um Informationen automatisch in menschlich lesbaren Form zu schreiben und zu aktualisieren. Die wichtigesten Merkmale so einer Dokumentation sind:
- Verständlichkeit: der Format sollte für alle lesbar und verständlich sein
- Automation: Entwickler haben selten Zeit eine Dokumentation zu pflegen
- Einfachheit: eine Erweiterung der Informationen sollte unkompliziert sein
Solch ein Dokumentationswerkzeug durchsucht den Quellcode des Systems und stellt detaillierte Informationen darüber bereit, welcher Entwickler wann und wieviel zum Microservices beigetragen hat. So können Mitarbeiter sehen an wem sie sich in bestimmten Fällen wenden können. Mithilfe von Daten aus verschiedensten Systemen, wie Continuous-Integration-Servern, von Versionsverwaltungsprogrammen und Issue-Tracking-Systemen, wird eine übergreifende Dokumentation erschaffen. [FOWL08]
Serverless
Serverless steht für Serverless computing und wird in zwei Bereichen eingesetzt:
- Es wird komplett auf die serverseitige Logik verzichtet und stattdessen werden Cloud-Services von Drittanbietern integriert. Übliche Anwender sind Single-Page-Webanwendungen und mobile Apps. Zu solchen Cloud-Services zählen Datenbanken, Authentifizierungsmechanismen und so weiter. Weshalb dieser Typ auch Backend as a Service genannt wird.
- Ein anderer Bereich von Serverless ist Function as a Service (FaaS). In diesem Szenario wird serverseitige Logik immer noch vom Entwickler geschrieben, jedoch verpackt in Container und von einer Cloud gemanagt. Diese Container sind zustandslos, ereignisgesteuert und kurzlebig.
Die folgende Abbildung zeigt die Unterschiede zwischen der üblichen Architektur und Serverless. Die Authentifizierung erfolgt über den Cloud-Service. Der Client hat Zugriff auf die Produkt-Datenbank, welche von Drittanbietern gehostet wird. Ein Teil der früheren Serverlogik der alten Architektur kann in den Client implementiert werden, siehe Single-Page-Webanwendung. Mit HTTP-Anfragen kann über die API eine Suche in der Datenbank getriggert werden - es ist nicht nötig, dass ständig ein Server am laufen sein muss. Es ist möglich Teile von eigenem Quellcode zu verwenden, falls die Programmiersprache unterstützt wird. Die Funktionalität "Kaufen" kann ebenfalls durch "Function as a Service" ersetzt werden. Zum einen, um den Client leichtgewichtiger zu halten, zum anderen aus Sicherheit. [ROBE18]
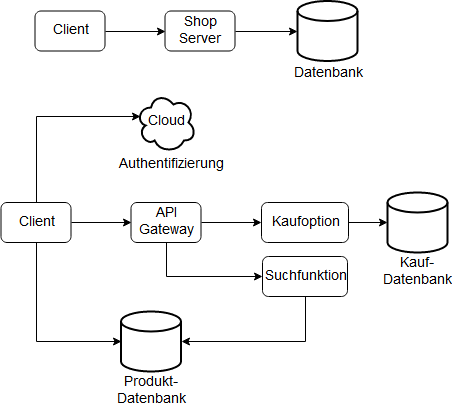
Drei Schichten-Architektur und Serverless, Abbildung angepasst aus [ROBE18]
Vereinfacht ausgedrückt - FaaS ist eine Ausführung von Backend-Quellcode ohne dabei einen eigenen Server oder dauerhaft arbeitende Serverprogramme laufen zu haben. FaaS ist darauf ausgelegt innerhalb kürzester Zeit (Millisekunden) je nach Anfrage benötigte Anwendungen zu starten und zu beenden. Die Vorteile sind eine Vereinfachung der Architektur durch den Wegfall einer Schicht und Übergabe der serverseitigen Logik an die Cloud-Services. Die Einsparung von Entwicklungs-, Installations- und Instandhaltungsaufwänden zählt ebenfalls zu den Vorteilen gegenüber der üblichen Drei-Schichten-Architektur. [ROBE18]
Unterschiede zu monolithischen Anwendungen
Die folgenden Kapiteln gehen auf die Vor- und Nachteile von Microservices gegenüber einer monolithischen Architektur. Die Nachteile eines Monoliths wurden in der Einführung beschrieben.
Vorteile
Der offensichtlichste Vorteil welchen Microservices mit sich bringen ist eine bessere Übersicht von Quellcode. Jeder Service ist sauber logisch und technisch von anderen getrennt, was es viel einfacher macht neue Entwickler reinzubringen. Wenn ein Microservice modifiziert werden soll, muss nicht die gesamte Architektur deswegen verändert werden, weil es keine Abhängigkeiten zu anderen Microservices gibt. Dies favorisiert eine kontinuierliche Entwicklung, weil von vorne rein viel weniger Raum für Querabhängigkeiten im Quellcode entsteht. Daraus resultiert eine erhöhte Einsatzfähigkeit, kürzere Entwicklungszeiten und bessere Umsetzung von innovativen Lösungen - Continuous Integration und Continuous Delivery. Microservices haben eine höhere Resistenz gegenüber Fehlern, da aufgrund ihrer Größe der Quellcode übersichtlicher ist und die Kommunikation mit anderen Microservices über klar definierte Schnittstellen erfolgt. Daraus resultiert ein weiterer Vorteil: Unabhängigkeit in der Entwicklung. Jeder Dienst wird autonom von einem Team entwickelt. Laut Amazon sollte ein Teams maximal so groß sein, dass es von zwei Pizza satt wird, also nicht mehr als ein Dutzend Entwickler.Es gibt ebenfalls eine Regel der halben Pizza, wovon ein zwei Mann Team satt wird. Die optimale Größe von Microservice Entwicklerteams variiert also zwischen zwei bis zwölf Mitgliedern.
Microservices vereinfach das schreiben von Tests aufgrund ihrer Granularität und Unabhängigkeit, was auch zur besseren Fehlereingrenzung führt. Jedes einzelnes Microservice kann in komplett anderer Programmiersprache geschrieben sein und sich technologisch komplett unterscheiden. So kann ein Service flexibel auf die kommenden Forderungen reagieren und sich mit der zeit anpassen, was zu einem langlebigen Programm führt. Allerdings hat es sich herausgestellt, dass Microservices eher verworfen und neu realisiert werden, anstatt sich auf lange Sicht darum zu kümmern. Im Gegensatz dazu kann eine monolithische Architektur zwar mehrere Dienste oder Komponenten enthalten - sie bilden aber trotzdem ein Ganzes und haben eine Programmiersprache. Bei einem Ausfall, können andere Microservices weiterarbeiten und ihren Beitrag zur Funktionalität der Applikation leisten. Ein immenser Vorteil eines Microservice ist die Möglichkeit in anderen Systemen wiederzuverwenden, solange die Schnittstelle richtig konfiguriert ist. [LEWI14], [NAMI14], [RICH17]
Nachteile
Die Kommunikation zwischen den Microservices und der Applikation geschieht nur über die Schnittstellen, was zu einer großen Menge an Remote Calls führt. Remote Calls verbrauchen mehr Ressourcen als In-Prozess Calls einer monolithischen Struktur. Ein weiterer großer Nachteil ist, dass Microservices zuerst partitioniert werden müssen. Am Anfang eines Systems ist nicht unbedingt offensichtlich wie es in Zukunft aussehen wird und der Aufwand einer Microservice-Architektur ist kann zu immens erscheinen. Jedes Service braucht einen klar definierten Anwendungsfall und muss frei von unnützen Funktionalitäten sein. Das kann wie im Falle von Amazon zu hunderten Microservices führen und dementsprechend dutzende Teams. Kommunikation zwischen diesen Entwicklerteams ist von entscheidender Bedeutung, denn Anwendungsfälle können sich über mehrere Services spannen. Monolithische Systeme können ebenfalls in einzelne Dienste aufgebrochen werden. Je größer eine Applikation ist, desto komplizierter ist die Umstrukturierung, denn zuerst müssen alle internen Abhängigkeiten aufgelöst werden. Microservices beanspruchen mehr Ressourcen, weil die Menge an monolithische Instanzen N ersetzt wird durch die Menge an Microservice-Instanzen N x M. Beim Einsatz von JVM oder deren Äquivalenten für die Isolierung einzelner Microservices steigt der Overhead ins M-fache der eingesetzten JVM-Runtimes.
Obwohl die kompakte Größe eines Miroservice das Schreiben von Testfällen erleichtert, wird durch die Komplexität der gesamten Architektur das Testen insofern schwieriger, dass die Zusammenarbeit mit anderen verteilten Diensten überprüft werden muss. Dezentralisierte Datenverteilung ist ein weiterer wichtiger Punkt. In dieser Architektur ist es üblich eine Datenbanklösung pro Service zu haben, wodurch Probleme mit der Datenkonsistenz auftretten können. Die Komplexität die verteilten Systeme zu managen und einzusetzen ist entsprechend höher als mit Monoliths, weil sie in komplett anderen Technologien und Sprachen umgesetzt sein können. [LEWI14], [NAMI14], [RICH17]
Die nächststehende Tabelle führt die Vor- und Nachteile kurz nochmal zusammen.
| Vorteile | Nachteile |
|---|---|
| Kompakter Quellcode | Größerer Ressourcenbedarf |
| Leichterer Einstieg ins Team | Use Cases nicht eindeutig |
| Erhöhte Einsatzfähigkeit | Sehr komplex |
| Kürzere Entwicklungszeiten | Überhang an Services möglich |
| Autonome Services | Testsfälle werden komplexer |
| Kleine dedizierte Teams | Abhängig von Schnittstellen |
| Resistent gegen Ausfall | Probleme mit Datenkonsistenz |
| Business Case abhängig | Aufwändig zu managen |
| Technologie unabhängig | Großer Kommunikationsaufwand pro Team |
| Wiederverwendbare Services |
Die Microservice-Architektur ist vorteilhaft, wenn die Rede um eine flexible und dennoch robuste Software geht.
Abgrenzung zu Self-Contained Systems
Self-contained Systems (SCS) ist ein Architekturmuster, der den Fokus auf Separation einer Funktionalität in mehrere unabhängige Systeme legt. Aus der Kollaboration dieser Systeme entsteht ein neues logisches System. So werden Probleme von großen monolithischen Systemen umgangen, da sie ständig wachsen und nicht mehr wartbar werden.
Sie sind den Microservices sehr ähnlich und teilen mit ihnen viele Merkmale. Zu diesen Merkmalen gehören unabhängige Einheiten, Anpassung von organisatorischen und architektonischen Grenzen, Diversität in technologischen Auswahl und dezentralisierte Infrastruktur. Dennoch gibt es einige Unterschiede:
- Ein Microservice ist üblicherweise kleiner als ein SCS
- Es gibt normalerweise weniger SCSs als Microservices, ein Shop kann 5-25 SCSs haben oder bis zu 100 Microservices
- SCSs sollten nicht miteinander kommunizieren, was für Microservices bis zu einem gewissen Grad in Ordnung ist
- SCSs besitzen eine UI, während Microservices die UI üblicherweise (nicht immer) in eigenes Service auslagern
- Microservices werden normalerweise auf der Logikschicht integriert und SCSs auf der UI-Schicht
Es ist möglich Self-contained Systems weiter in die Microservices aufzuteilen. SCS fokussiert sich auf großen Projekten und Aufteilungen in mehrere Teams. Bei Microservices sind eher kleine Teams oder einzelne Entwickler im Einsatz, was erlaubt Continuous Delivery einfacher anzuwenden, robustere Systeme zu entwerfen oder einzelne Services zu skalieren. Microservices sind vielseitiger, aber Self-contained Systems lösen Probleme mit der Architektur und Organisation großer Projekte. [SCSVSM]
Microservices als Front-Ends
Für Webanwendungen gewinnt Front-End immer mehr an Bedeutung, während Back-End weniger wichtig wird. Der Trend geht in Richtung einer 90 zu 10 Aufteilung zu Gunsten von Front-End. Der monolithische Design ist für Front-End zu schwerfällig, so dass eine Aufteilung in kleinere Module nötig ist. Der aktuelle Trend heißt "Micro Front-Ends" und Unternehmen, wie Spotify und Zalando sind schon umgestiegen. Das sind einige der Umsetzungsmöglichkeiten:
- Eine Kombination aus mehreren Frameworks auf einer Webseite ohne das die Webseite aktualisiert werden muss.
- Mehrere Singe-Page-Applikationen, die über verschiedene URLs zugänglich sind. Diese Applikationen nutzen Paketverwaltung für geteilte Funktionalität.
- Micro-Apps in IFrames verpacken und über APIs koordinieren.
- Verschiedene Module können über einen gemeinsamen Event-Bus kommunizieren. Jedes Modul benutzt sein eigenes Framework und handelt nur eingehende und ausgehende Events.
- Mithilfe von einem Web-Beschleuniger verschiedene Module zu integrieren.
- Webkomponenten als eine Integrationsschicht zu verwenden. Sie erlauben wiederverwendbare Komponenten in Webanwendungen und Webdokumenten zu erstellen.
- React-Komponenten in einer Blackbox zu isolieren. Hier wird der Zustand einer Applikation im Komponenten festgehalten und über die API werden nur die Eigenschaften zugänglich gemacht. [SÖDE17]
| Vorteile | Nachteile |
|---|---|
| Unabhängig | Erhöhter Betriebsaufwand |
| Hohe Testbarkeit | Erhöhte Komplexität (z.B. Infrastruktur, Kommunikation) |
| Unabhängige Technologiestacks | Schlechtere Performance |
| Unabhängig im Fehlerfall | Restrukturierung kann sehr komplex werden |
| Parallele Entwicklung möglich |
Tabelle angepasst aus [LECH17]
Diese Abbildung stellt Front-Ends in verschiedenen Architekturen dar. In jeder bildet das Front-End ein ganzes System; entweder für sich alleine oder als ein Monolith mit Back-End und Datenbank.
Monolithische Front-Ends, Abbildung entnommen aus [GEER17]
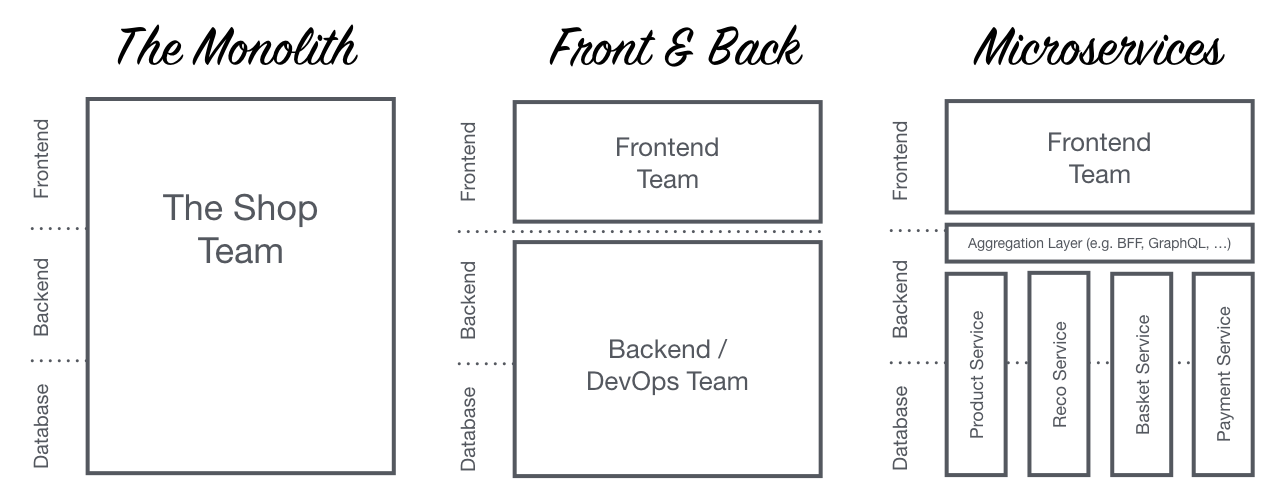
In dieser Abbildung ist eine mögliche Aufteilung eines monolithischen Front-End in Micro Front-Ends in vertikaler Ebene dargeboten. Wie auch im Microservices Back-End Bereich ist hier jedes Team für einen Dienst zuständig: Product, Checkout, etc. Links in der Abbildung sind die drei Schichten zu sehen:
- Front-End
- Back-End
- Datenbank
Jedes Entwicklerteam behandelt alle drei Bereiche seines Services. Das korreliert auch mit "klassischen" Microservices in dem Sinne, dass Polyglot Persistence eingesetzt wird - eine Datenbank pro Service.
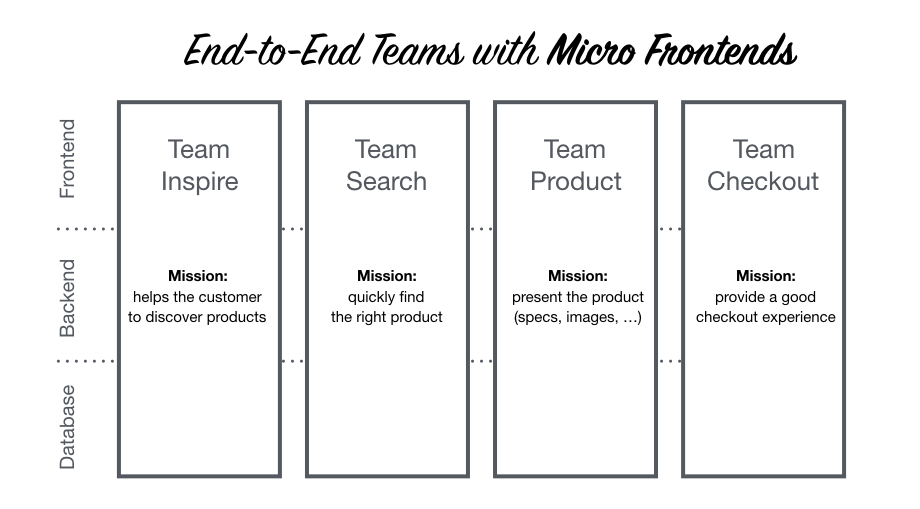
Micro Front-Ends, Abbildung entnommen aus [GEER17]
Einsatz von Microservices
Es ist schwierig zu entscheiden in welchen Fällen Microservices eingesetzt werden sollten, denn viele Probleme mit monolithischer Architektur tauchen erst mittelfristig auf und keiner möchte die zusätzliche Komplexität am Anfang eines Projekts auf sich nehmen. Die Entwicklung einer verteilten Architektur ist langwierig. Deswegen sind für Startups, die auf rapide Entwicklung und Versionierung aus sind, Microservices nicht unbedingt die erste Wahl. Allerdings können in späterer Entwicklung Probleme mit der Skalierung auftretten was zu einer funktionellen Dekomposition führt. Es könnte schwierig sein die internen verworrenen Abhängigkeiten aufzulösen.
Genauso wichtig wie die Frage "Wann", ist die Frage "Wie" - wie soll die Aufteilung von Microservices aussehen? Eine Möglichkeit ist die Dekomponierung nach Business Capabilities, die andere nach Domain-Driven Design. Die beiden Fälle wurden in vorherigen Kapiteln erklärt. Dekomponierung nach Anwendungsfällen definiert Services die für bestimmte Aktionen verantwortlich wären, wie z.B. Shipping Service. Partitionierung nach Nomen (Ressourcen) definiert Services für Operationen an Ressourcen oder Entitäten, wie z.B. Account Service. Ein Service sollte ein Set an Verantwortlichkeiten haben, wessen Klassen nach Single Responsibility Principle (SRP) entworfen werden. SRP besagt, dass jede Klasse eine einzige fest definierte Aufgabe im System erfüllen muss und diese Zweckerfüllung übernehmen lediglich dessen Methoden.
Den Weg von Monolith zu Microservices gingen unter anderem Netflix, Amazon und EBay. Netflix generiert bis zu 30% des weltweiten Datenverkehrs und besitzt eine massive serviceorientierte Architektur, welche über eine Milliarde Zugriffe auf ihren Video-Hostingdienst von 800 verschiedenen Geräten aus verwaltet. Amazon benutzt von 100 bis 150 Microservices beim Einsatz dessen Webseite. [RICH17]
Quellen
[EVAN15]: Evans, Eric: Domain‐Driven Design Reference, Domain Language Inc. pp vi-2, 2015, URL: http://domainlanguage.com/wp-content/uploads/2016/05/DDD_Reference_2015-03.pdf (letzter Zugriff: 06.06.2018)
[FOWL08]: Fowler, Martin: HumaneRegistry, 01.12.2008, URL: https://martinfowler.com/bliki/HumaneRegistry.html (letzter Zugriff: 27.05.2018)
[FOWL14]: Fowler, Martin: BoundedContext, 15.01.2014, URL: https://martinfowler.com/bliki/BoundedContext.html (letzter Zugriff: 06.06.2018)
[GEER17]: Geers, Michael: What are Micro Frontends?, 2017, URL: https://micro-frontends.org/ (letzter Zugriff: 03.06.2018)
[MIRI17]: Miri, Ima: Microservices vs. SOA, 04.01.2017, URL: https://dzone.com/articles/microservices-vs-soa-2
[LECH17]: Lechner, Alexander: Micro-Frontends - Die bessere Art User Interfaces zu implementieren?, 15.11.2017, URL: https://www.it-economics.de/blog/2017-11/micro-frontends-die-bessere-art-user-interfaces-zu-implementieren (letzter Zugriff: 02.06.2018)
[LEWI14]: Lewis James; Fowler, Martin: Microservices, a definition of this new architectural term, 25.03.2014, URL: https://martinfowler.com/articles/microservices.html (letzter Zugriff: 31.05.2018)
[NAMI14]: Namiot, Dmitry; Sneps-Sneppe, Manfred: On Micro-services Architecture, International Journal of Open Information Technologies ISSN: 2307-8162 vol. 2, no. 9, 2014, URL: https://cyberleninka.ru/article/v/on-micro-services-architecture (letzter Zugriff: 26.04.2018)
[PECK17]: Peck, Nathan: Microservice Principles: Decentralized Governance, 05.09.2017, URL: https://medium.com/@nathankpeck/microservice-principles-decentralized-governance-4cdbde2ff6ca (letzter Zugriff: 24.05.2018)
[PIEN16]: Pientka, Frank: Wie lassen sich Microservice-Muster effizient umsetzen?, 09.02.2016, URL: https://www.informatik-aktuell.de/entwicklung/methoden/wie-lassen-sich-microservice-muster-effizient-umsetzen.html, (letzter Zugriff: 01.06.2018)
[RICH15]: Richardson, Chris: Pattern: Building Microservices: Using an API Gateway, 15.06.2015, URL: https://www.nginx.com/blog/building-microservices-using-an-api-gateway/ (letzter Zugriff: 9.06.2018)
[RICH17]: Richardson, Chris: Pattern: Microservice Architecture, 2017, URL: http://microservices.io/patterns/microservices.html (letzter Zugriff: 31.05.2018)
[ROBE18]: Roberts, Mike: Serverless Architectures, 22.05.2018, URL: https://martinfowler.com/articles/serverless.html (letzter Zugriff: 27.05.2018)
[SCSVSM]:SCS vs. Microservices, URL: http://scs-architecture.org/vs-ms.html (letzter Zugriff: 02.06.2018)
[SÖDE17]: Söderlund, Tom: Micro frontends—a microservice approach to front-end web development, 06.07.2017, URL: https://medium.com/@tomsoderlund/micro-frontends-a-microservice-approach-to-front-end-web-development-f325ebdadc16 (letzter Zugriff: 31.05.2018)
[TATV16]: TatvaSoft: The Difference between Web Services and Micro Services, 30.06.2016, URL: https://www.tatvasoft.com/blog/the-difference-between-micro-services-and-web-services/