Streaming Architectures
"Sitting"-BigData?
Um möglichen Verwirrungen entgegenzuwirken, soll vorab direkt auf einen wichtigen Punkt hingewiesen werden: beim Lesen von "Streaming Architectures" vermag der geneigte Internet-Nutzer an On-Demand-Mediendienste in den Reihen von Spotify, Youtube und Weiteren denken. Diese Content Delivery Networks "streamen" zwar, haben aber mit dem Fokus dieses Kapitels nur nebensächlich zutun. Die Ausarbeitung thematisiert einen neuen Ansatz der skalierbaren Softwarearchitektur, der aber durchaus als Antwort auf die Bedürfnisse der genannten Plattformen interpretiert werden kann. Der gemeinsame Nenner beider Begebenheiten ist ein altbekanntes Buzzword: BigData. Ein kurzer Einblick in die (gewagte) Definition und Entwicklung des BigData-Trends zeigt, auf welche Probleme die Streamingarchitektur eine Antwort sein soll. Dabei sind zwei Aspekte von Bedeutung: Datenwachstum und Infrastrukturwachstum.
Datenwachstum
BigData wurde schon zu Anfang der 2010er zum Imperativ für kompetitive Technologie-Unternehmungen. Studien zeigten, dass Organisationen, die analytics-getriebene Vorsprünge aktiv durch Investitionen verfolgten, mit mehr als doppelt so hoher Wahrscheinlichkeit ihre Konkurrenz signifikant hinter sich ließen[ZIKO13]. Dementsprechend ist es nachvollziehbar, dass BigData als Schirmherr analytischer IT-Infrastrukturen einen solchen "buzz" entwickelte. Dessen Marktvolumen konnte ein stetiges, nicht unerhebliches Wachstum verzeichnen:
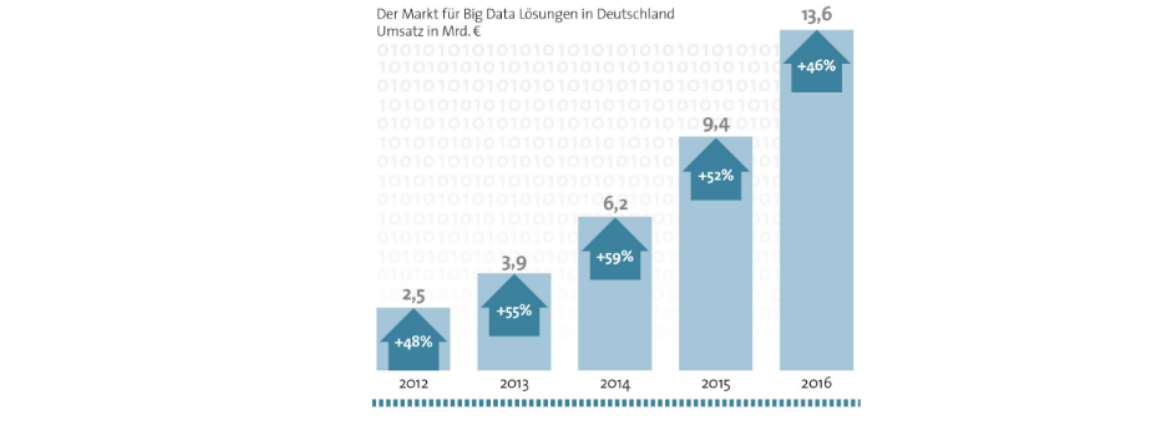
BigData Marktwachstum in Deutschland. Quelle: https://proteus-solutions.de/~Unternehmen/News-PermaLink.asp?PS=tM.F04!sM.NI41!Article.961265
IBM nennt als einer der Branchengiganten Eigenschaften, die BigData greifbarer machen sollen: Volumen, Vielfältigkeit und Geschwindigkeit[ZIKO13]. Diese Deskriptoren bilden die Brücke zwischen Marktwachstum und technischen Anforderungen. Volumen ist die offensichtliche Eigenschaft und beschreibt das Anfallen von Daten in einem Maße, welches die Entwicklung besonderer Umgangsstrategien vorschreibt. Mit Vielfältigkeit wird aufgenommen, dass Daten strukturiert, unstruktiert und über die Zeit restrukturierend mit beliebigen Typen auftreten. Dass dies in einer enormen Geschwindigkeit stattfindet, stellt die größte Herausforderung an IT-Infrastrukturen und Ingenieure. Das Ziel, diese Datenüberfülle analytisch zu untersuchen um Wissen zu generieren, hat zur Entwicklung hochskalierbarer Persistierungsstrategien beigetragen. Es wird also das Mantra verfolgt, alle anfallenden Daten zu speichern, ganz im Sinne des plakativen Ausspruchs "Daten seien das Gold des 21. Jahrhunderts" und um keine Chance eines kompetitiven Vorteils außer Acht zu lassen. Verlorene Informationen werden wie verlorener Gewinn wahrgenommen. Mit diesem Ansatz entstanden Data Lakes – Systeme, die als "Datengrab" dienen um einen historisch vollumfänglichen Zugang für Analytiker zu garantieren. Beispielsweise bildet das Hadoop File System die Basis eines solchen Data Lakes, in den alle Informationen effizient und skalierbar einlaufen sollen.
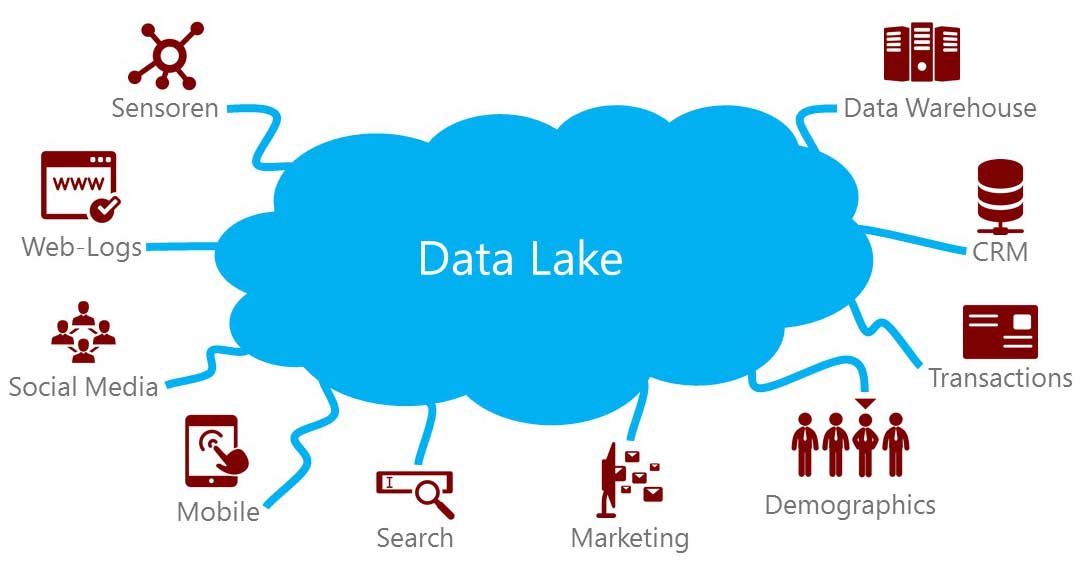
Data Lake Visualisierung. Quelle: https://www.pmone.com/data-lake/
Diese Strategie hat sich über das letzte Jahrzehnt bewährt. Es schien eine valide Methode zu sein, Daten massiv anzusammeln und dann bei Bedarf Analysen zu unterziehen – auch Batch Processing genannt. Allerdings muss bedacht werden, mit welcher Geschwindigkeit Data Lakes zukünftig wachsen müssen. Als sie sich im Verlauf der letzten Dekade hinter der IT von Unternehmen etablierten, wurde die Menge der jährlich weltweit produzierten Daten noch mit unter 5 ZT (1 Zettabyte = 1.000.000.000 Terabyte) beziffert. Der bekannte Hersteller für Speicherlösungen Seagate prognostiziert das weltweite Datenaufkommen mit 160 ZT pro Jahr bis 2025:
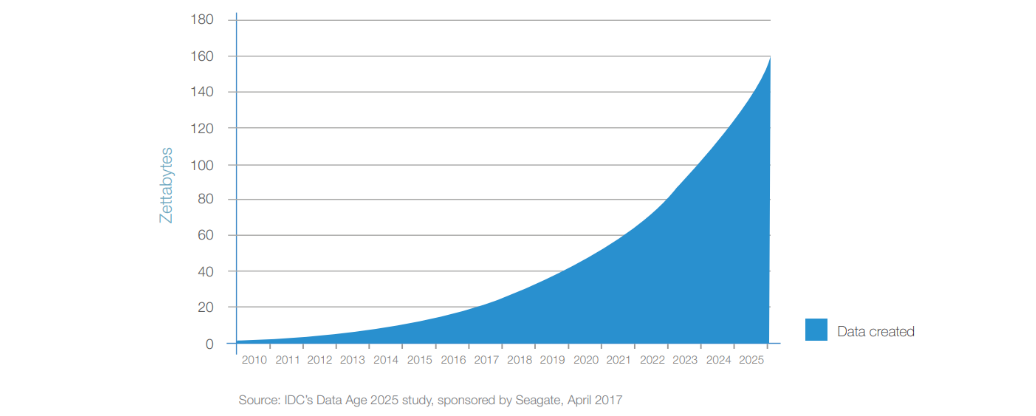
Exponentielles Wachstum der global erzeugten Datenmenge. Entnommen aus [REIN17]
Die globale Datensphäre wächst also exponentiell schnell und verdoppelt ihre Größe zirka alle zwei Jahre. Cisco als Unternehmen und Experte für Datacenter-Lösungen prognostiziert demgegenüber die Rate, mit der die weltweit zur Verfügung stehende Speicherkapazität wächst, als linearen Trend:
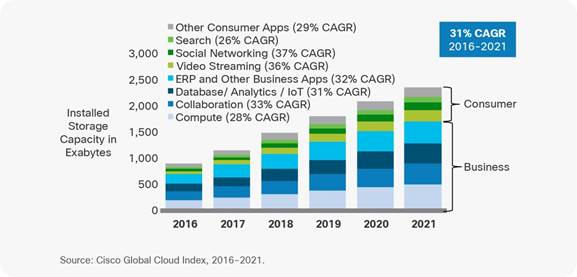
Lineare Prognose des weltweit verfügbaren Speicherplatzes. Quelle: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/global-cloud-index-gci/white-paper-c11-738085.html#_Toc503317524
Zusätzlich wird erwartet, dass das Internet-of-Things die Geschwindigkeit der Datenerzeugung stark erhöhen wird. Die täglichen per Automation immer impliziteren Interaktionen des Nutzers mit Online-Diensten sollen sich mehr als verzehnfachen:
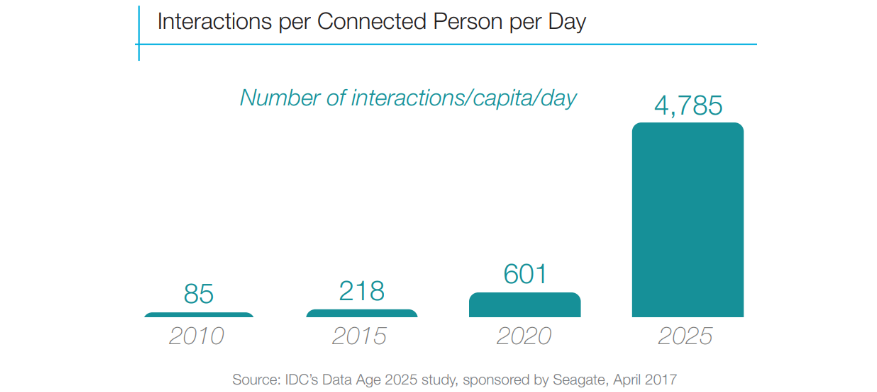
Prognose der Menge täglicher Nutzerinteraktionen. Entnommen aus [REIN17]
Diese Beobachtungen werfen die Frage auf, ob Data Lakes wirklich eine nachhaltige Strategie darstellen können. Sie hatten zu ihrer Entstehungszeit eine Daseinsberechtigung, die aber in der Zukunft in ein skeptisches Licht rückt. Dabei spielt es keine Rolle, ob die zugrundeliegende Hardware im Unternehmen vor Ort oder in der vermeintlich skalierbaren Cloud untergebracht ist. Beide Umgebungen sind von den genannten Problemen betroffen. Die IT-Branche sieht sich also mit dem Risiko konfrontiert, dass die Data Lakes ohne proaktive Maßnahmen wortwörtlich "überlaufen". Auf die reine Kapazitätsskalierbarkeit der Systeme kann sich augenscheinlich nicht mehr verlassen werden.
Infrastrukturwachstum
Erschwerend kommt zu den genannten Aspekten ein aus Sicht der IT fundamentales Ingenieursproblem hinzu: Data Lakes sind in den seltensten Fällen eine One-Solution-Serves-All Lösung. Unternehmen, die ihren kompetitiven Vorteil durch analytische, informationszentrische Dienste erwirtschaften, sind oft schnellwachsend. Das bedeutet für deren IT-Landschaft einen stetigen Veränderungsprozess mit sehr kurzen Iterationen zwischen Systemerweiterungen und neuen Serviceleistungen. Trotz guter Planung kann dies zu heterogenen Umgebungen führen[KREP14]. Insbesondere dann, wenn der Datenfluss persistiert und analysiert wird, werden Systeme gekoppelt, denen sehr unterschiedliche Bedürfnisse und Ziele zugrunde liegen. Beispielsweise Dokumenten-Storages für unstrukturierte User-Inhalte, Recommendation-Engines, Ad-Serving-Systems, Newsfeed-Engines, Graph-Datenbanken für Profilverknüpfungen, Safety-/Security-Monitoring, OLAP Query-Engines und beliebige weitere Dienste sind denkbar, die mit der Zeit hinzugefügt werden. All diese Komponenten und Module stehen in unterschiedlichem Umfang in Verbindung und erzeugen miteinander Kommunikationsdaten, die selbst wiederum von meta-analytischem Interesse sein können:
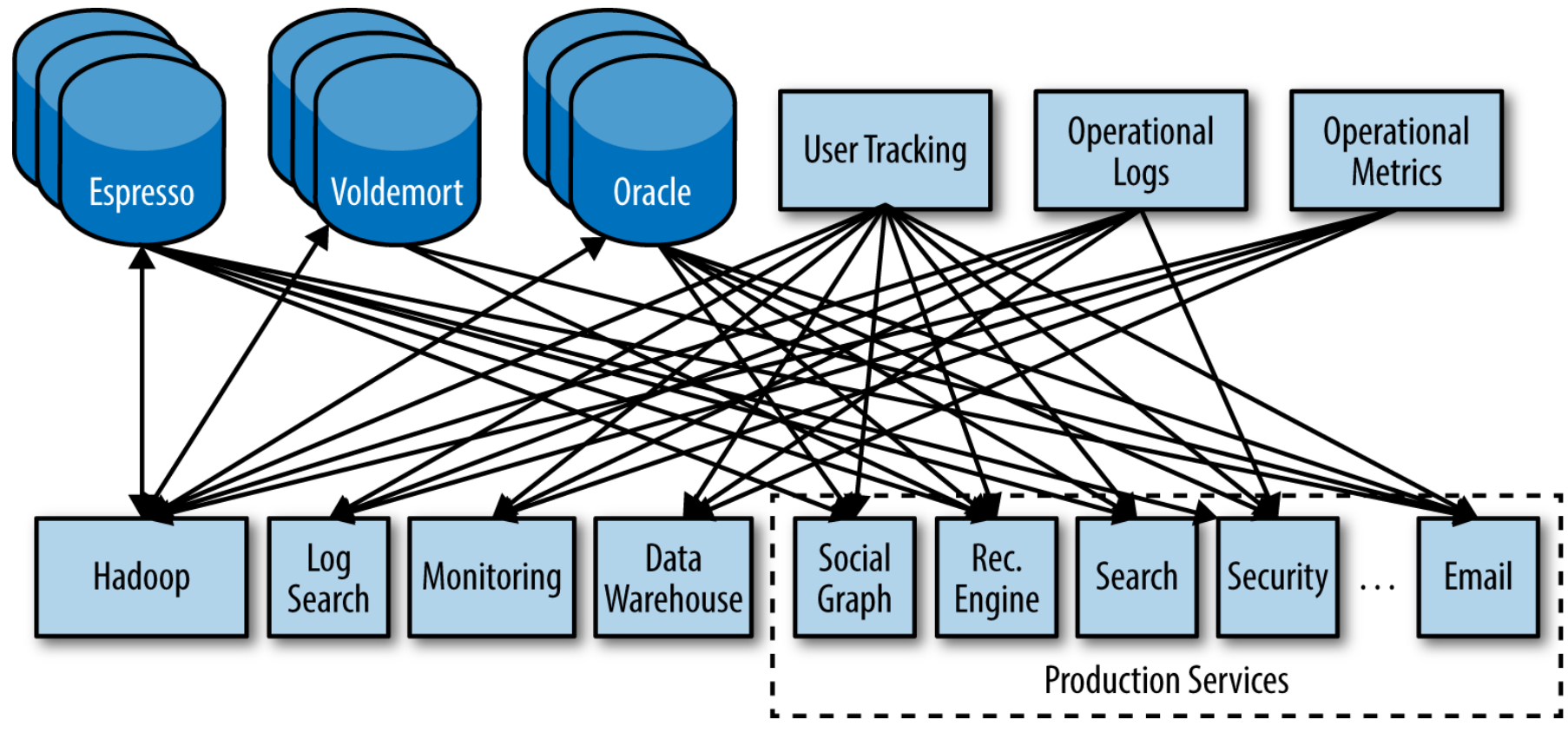
Beispiel einer vollvernetzten Infrastruktur. Entnommen aus [KREP14]
Zu beachten ist, dass Daten meist in beiden Richtungen fließen und so bei Vollvernetzung der Dienste O(N^2) Datenpipelines entstehen können[KREP14]. Entwicklung, Pflege und Wartung dieser Kommunikationslandschaft sind offensichtlich unannehmbare Hürden wenn das System mit dem Erfolg von BigData wachsen muss. Instabilitäten sind dann nicht mehr zu vermeiden, da selbst die beste Dokumentation nicht abbilden kann, welche Folgen die Anpassung oder Erweiterung einer Schnittstelle für das Gesamtsystem bedeutet. Wenn sich die Eigenschaften der Datenerzeugung oder -verarbeitung einer Schnittstelle verändern sollten, müssen alle damit verknüpften Datapipelines angepasst werden.
Für betroffene Unternehmen ist es also erstrebenswert, eine Plattform einzusetzen, die sowohl den besonderen Ansprüchen an die infrastrukturelle Erweiterbarkeit genügt, als auch eine Antwort auf analytische Ziele liefert, also Einsicht in alle anfallenden Informationsereignisse des gesamten Systems garantiert ohne Nachteil gegenüber dem Data Lake-Ansatz, der gemessen an seiner enormen Abhängigkeit von Speicherkapazitäten kritisch betrachtet werden muss.
Im Idealfall ergibt sich eine Lösung, die alle Komponenten vollverknüpft, Schnittstellen so implementiert, dass sie sich ohne Anpassungen an ihren Komplementären verändern können, gleichzeitig von Kapazitätslimits der Persistierung entkoppelt ist und neue Komponenten in beliebigem Umfang aufnimmt. Ein solches Daten-Repository im Zentrum einer Stern-Topologie würde für die perfekte Komponentenisolation und Datenintegration in einem einzigen System sorgen (siehe nachstehende Illustration).
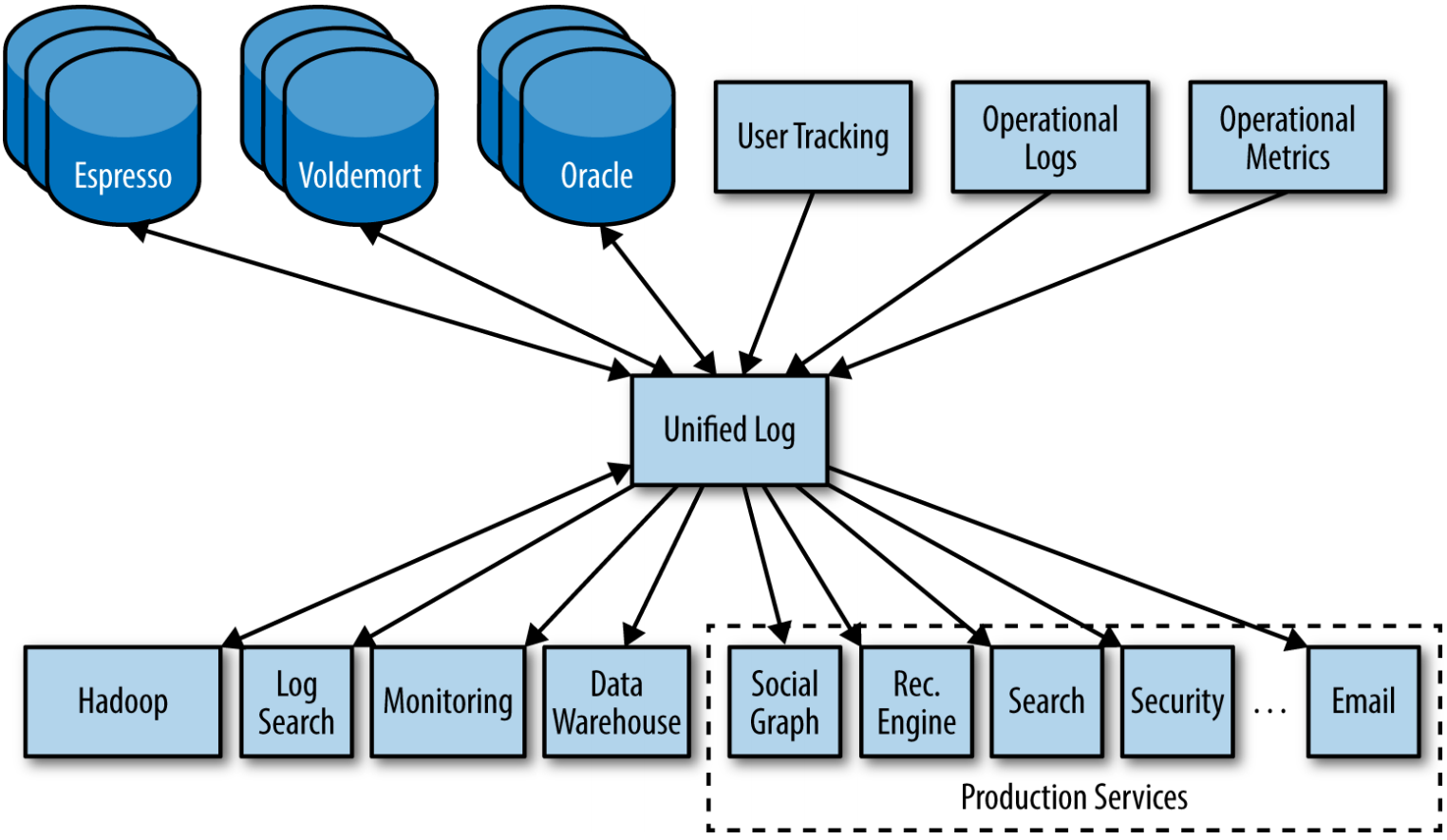
Lösung der Vollvernetzung durch eine Stern-Topologie. Entnommen aus [KREP14]
Dass sich diese konfliktären Ziele vereinigen lassen und eine gute Balance im Sinne des CAP-Theorems bilden können[KREP14], soll die vorliegende Ausarbeitung transportieren. Dabei wird auf eine Architektur eingegangen, die Eigenschaften von Database Management Systemen und Data Stream Management Systemen mit verteilten Kommunikationsprotokollen in ein neuartiges, hochskalierbares Infrastrukturmuster übersetzt.
Was bedeutet "Streaming Architecture"?
Im vorherigen Kapitel wurden Data Lakes mit Batch Processing assoziiert, also dem gestaffelten Verarbeiten von Daten in „Häppchen“. Beispielsweise eine analytische Transformation der Tagesgeschäftsdaten in einem Unternehmen durch nächtlich automatisierte Job-Scheduler. Demgegenüber steht das Stream Processing, welches offensichtlich ein zentrales Element der Streaming Architektur darstellt. Dieser Abschnitt soll das Umdenken von punktueller zu kontinuierlicher Verarbeitung motivieren.
Die Realität schreitet dauerhaft voran und setzt sich aus aufeinander folgenden Ereignissen zusammen. In der Vergangenheit haben wir an den Schnittstellen zwischen Echtwelt und IT Diskretisierungsmaßnahmen vorgenommen, um den Fluss der Ereignisse zu quantifizieren. Unsere IT-Systeme arbeiteten also mit Ausschnitten, obwohl dies die Realität eher geistlos wiederspiegelt. Batches entstanden als kumulierte Projektion des potentiell unendlichen Datenflusses, wenngleich die kontinuierliche Verarbeitung viel natürlicher erscheint. Dieser Umstand ist selbstverständlich nicht auf Unvermögen zurückzuführen, sondern eine erwartete Antwort auf die Fähigkeiten der zur Verfügung stehenden Technologien[DUNN16].
Mit steigender Performance von Hard- und Software wandelt sich nun auch die Art der Datenverarbeitungsparadigmen. Der erste Schritt war dabei Microbatching - die Verarbeitung in sehr kleinen Ausschnitten für schnellere Ergebnisse. Zur Umsetzung von Stream Processing im Sinne der Streaming Architekturen wird nun die Weiterentwicklung zur Echtzeitverarbeitung gewagt. Ereignisse werden also nicht mehr gesammelt, sondern sofort beim Auftreten interpretiert und weiterverarbeitet. Mit den im vorherigen Kapitel prognostizierten Datenvolumina scheint die Echtzeitanforderung allerdings utopisch. Die neuesten Evolutionen der hochperformanten Datenverarbeitung machen aber Stream Processing nicht nur möglich, sondern können auch das Problem der überlaufenden Data Lakes lösen. Wenn alle Daten in Echtzeit verarbeitet und analysiert werden können, müssen nicht mehr zwingend alle Informationen gespeichert werden. Lediglich komplexeres, abstraktes Wissen über alle parallelen Datenströme wird Kandidat für die Persistierung. Das bisherige Datengrab ändert dann seine Rolle zu einer Art "Daten-Goldlager" mit kalkulierbarer Größe dessen Inhalt sich auf tatsächliche Wertigkeiten konzentriert. Gleichzeitig werden Datenpipelines zwischen internen Systemkomponenten ebenfalls als Strom interpretierbar, auch Event Sourcing genannt. Es existiert dann keine Unterscheidung mehr zwischen Datenflüssen, die tatsächlich den Sinn der Rohdatentransmission erfüllen, und Folgen von Steuerinformationen, denn beide sind abstrahiert bloß nacheinander fließende Ereignisse. Stream Processing differenziert also nicht mehr. Es gibt nur noch Datenströme, egal ob sie Byteblöcke, Queries oder Sonstiges enthalten.
Mit dieser generalisierenden Sichtweise lässt sich nun die Streaming Architektur definieren. In ihr erfolgen alle Kommunikationen, ob zu Echtweltschnittstellen, Systemkomponenten oder Legacy-Systemen, in Form von Real-Time Streams. Die Architektur ist dabei in der Lage, die Menge und Geschwindigkeit der Ströme beliebig zu skalieren. Dieser neue Engineering-Ansatz macht das unendliche Wachstum der Data Lakes unnötig indem stattdessen die Nutzung der Daten selbst skaliert wird - der eigentliche Zweck der Data Lakes. Wenn die Softwarearchitektur informationszentrisch arbeitet und in der Lage ist, analytische Mehrwerte zu generieren, ohne dass eine Zwischenspeicherung erfolgen muss, wird die vollumfängliche Speicherung hinfällig.
Als gute Analogie kann man sich vorstellen, wie Goldsucher am Grund eines Baches nach Rohgold schürfen. Es scheint offensichtlich unsinnig das gesamte fließende Sediment inklusive Steinen, Pflanzenmaterial und Bergwasser in einen riesigen Tank umzuleiten um später darin zu suchen. Es ist deutlich effizienter und ressourcenschonender, direkt im fließenden Gewässer zu arbeiten und das vorbeilaufende Sediment zu filtern bis ein Rohgoldnugget hängen bleibt – wie es in der Tat auch getan wird. Die BigData-Infrastrukturen sind nun an einem Punkt, an dem die Idee der Goldschürfer mit der Streaming Architektur in das Software-Engineering aufgenommen wurde. Eine Open-Source Realisierung dieser wird durch Apache Kafka bereitgestellt.
Apache Kafka - Stream Repository
Im Gegensatz zu Lösungen wie IBM Websphere MQ, Java Messaging Service oder vergleichbaren Enterprise Messaging Systemen, ist Kafka eine javabasierte, verteilte Message Queue, deren primärer Design Constraint in extremer Skalierbarkeit und Bandbreite begründet ist[KREP11] und nicht nur den reinen Datenaustausch garantiert, sondern auch die nötigen infrastrukturellen Voraussetzungen schafft, um mit den in Kafka strömenden Daten analytische Transformationen auszuführen. Der Fokus auf "Data Ingestion" im BigData-Bereich ist der Vorteil zu generischen Publish-Subscribe-Patterns, die in diesem Kontext nicht die notwendigen Bandbreiten liefern könnten ohne die Consumer an ihre Performancegrenzen zu bringen. Wie eine solche Streaming Architektur technisch umgesetzt werden kann, lässt sich am Beispiel Kafkas gut analysieren und ist der Inhalt der folgenden Abschnitte.
Die Datenstruktur
Es wurde nun betont, dass Datenströme den Kern der Streaming Architektur darstellen. Diese müssen informationstechnisch mit einer Datenstruktur abgebildet werden, welche die abstrakten Eigenschaften strömender Daten teilt[SHAP17]:
Datenströme sind geordnet: Es existiert ein klares Verständnis darüber, welches Event vor oder nach anderen Events auftritt. Ströme sind also stärker mit Tupeln statt Mengen assoziiert. Zwei Ströme, die identische Events in unterschiedlicher Ordnung enthalten, sind verschieden. Hier liegt ein wichtiger Unterschied zu Datenbanktabellen, die per Definition ungeordnet sind (Anmerkung: Der "ORDER BY"-Befehl ist nicht teil des relationalen Modells).
Data Records sind unveränderbar: Aufgetretene Events gehen in die Systemhistorie ein und können nicht mehr angepasst werden. Ist ihr Ergebnis zu revidieren, dann erfolgt ein weiteres, inverses Event. Dies ist vergleichbar mit DBMS-Transaktionen mit dem Unterschied, dass in einer Datenbank nicht die Geschichte der Transaktionen gespeichert wird, sondern ihr kumulatives Ergebnis in Form eines updatebaren Tabelleneintrags – vorausgesetzt die Transaktion enthält keinen DELETE-Befehl nach dessen Ausführung die historische Information über die Existenz des Eintrags verloren geht.
Eventströme sind wiederholbar: Man kann sich gut nicht-wiederholbare Streams vorstellen (zum Beispiel eine Folge von TCP-Paketen auf einem Socket), aber die Geschäftslogik höherer Ordnung profitiert davon, die Vergangenheit der Events erneut erleben zu können. Im Falle von Fehlern, Systemerweiterungen, Monitorings usw. können einzelne Komponenten einfach auf einen älteren Zeitpunkt "zurückgespult" werden um dann den aktuellen, integren Zustand durch erneutes Abspielen der Vergangenheit zu erreichen. Diese temporale Entkopplung von Produzent und Konsument hat einen massiven Vorteil: Data Ingestion wird nicht durch die Performance der Consumer beschränkt.
Die entsprechende Datenstruktur ist also ein Event-Protokoll äquivalent zu einem commit log, einer unveränderbaren, ausschließlich erweiterbaren Sequenz temporal geordneter Data Records[KREP14] wie in der nachfolgenden Grafik dargestellt (durchaus vergleichbar mit einem Ledger im Sinne der Blockchain, allerdings mit dem Fokus auf Performance statt Sicherheit). In Kafka werden Streams durch solche Logs realisiert.
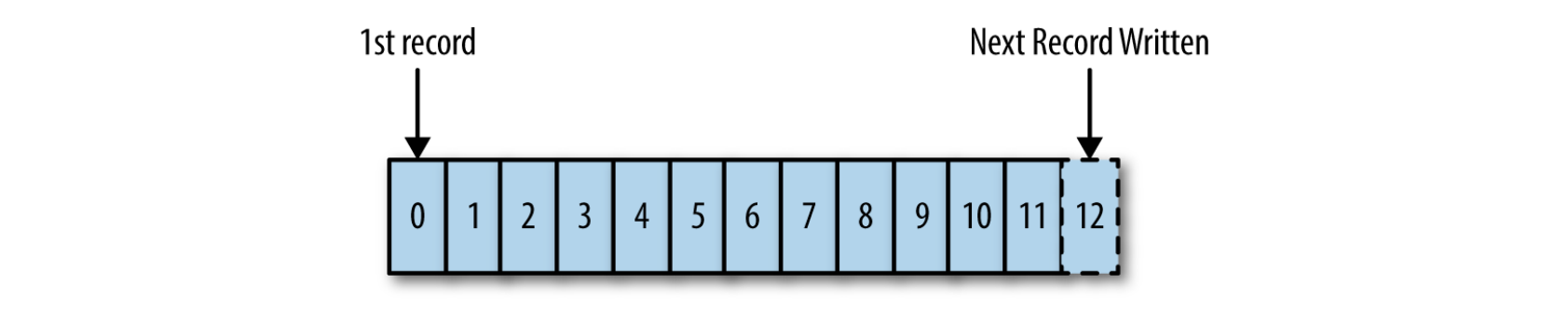
Darstellung eines Logs. Entnommen aus [KREP14]
Jedes Rechteck stellt einen Eintrag im Log dar, also die Folge der eintreffenden Events. Da das Log durch die Sequenz der Eintragsnummern sortiert ist, wird es von links nach rechts gelesen. Die Eintragsnummer entspricht dem eindeutigen Identifikator des Eintrags und dessen Inhalt. Events sind also eine Kombination aus key und value. Values können in dieser Interpretation beliebig sein. Binäre Blobs sind genauso möglich wie strukturierte JSON-Strings (Anmerkung: Auf die De-/Serialisierung von values wird später genauer eingegangen).
Die sequentielle Ordnung der Keys ist an ihr zeitliches erscheinen gebunden. Niedrige Keys sind vor höheren Keys aufgetreten. Dieses Verständnis des Keys als Zeitstempel hat den Vorteil der Entkopplung von physischen Uhren.
Die Idee der Log-Struktur ist sehr simpel und auf den ersten Blick nicht sehr unterschiedlich zu einer zeitlich geordneten Datei oder Tabelle. Es ist wichtig das Log als abstrakte Datenstruktur zu verstehen, welche speichert was wann passiert ist, nicht als konkreten Speicherbereich. So löst das Log ein Problem verteilter Systeme: Wenn zwei identische, deterministische Prozesse im gleichen Zustand beginnen und die gleichen Eingaben in der gleichen Reihenfolge erhalten, produzieren sie die gleichen Ausgaben und enden im gleichen Zustand[KREP14]. Im Distributed Systems Engineering ist diese Einsicht nicht neu, aber die Implikationen des einfachen Log-Patterns sind für Enterprise Architekturen bedeutend: Der interne Zustand von Komponenten kann durch eine einzige Zahl beschrieben werden. Die Sequenznummer des höchsten Eintrags, der von einer Komponente auf einem Log verarbeitet wurde, lässt dessen Zustand deterministisch nachvollziehen. So wird ein diskretes, event-basiertes Verständnis der Zeit geschaffen und erlaubt komponentenübergreifende Vergleichbarkeit bei vollständiger Entkopplung von schwer synchronisierbaren, lokalen, physischen Uhren.
Datenfluss
Wenn jede logische Datenquelle mit seinem eigenen Log definiert wird, kann jede an der Datenquelle interessierte Komponente die in das Log geschriebenen Events in seiner eigenen Geschwindigkeit lesen, intern verarbeiten und seine Position auf dem Log um einen Schritt verschieben. Diese spezielle Form des Publish-Subscribe-Patterns überlässt es dem Konsumenten seinen Datenabruf zu steuern. Der Produzent muss nicht auf die Verarbeitung warten, wie es die nachstehende Grafik zeigt.
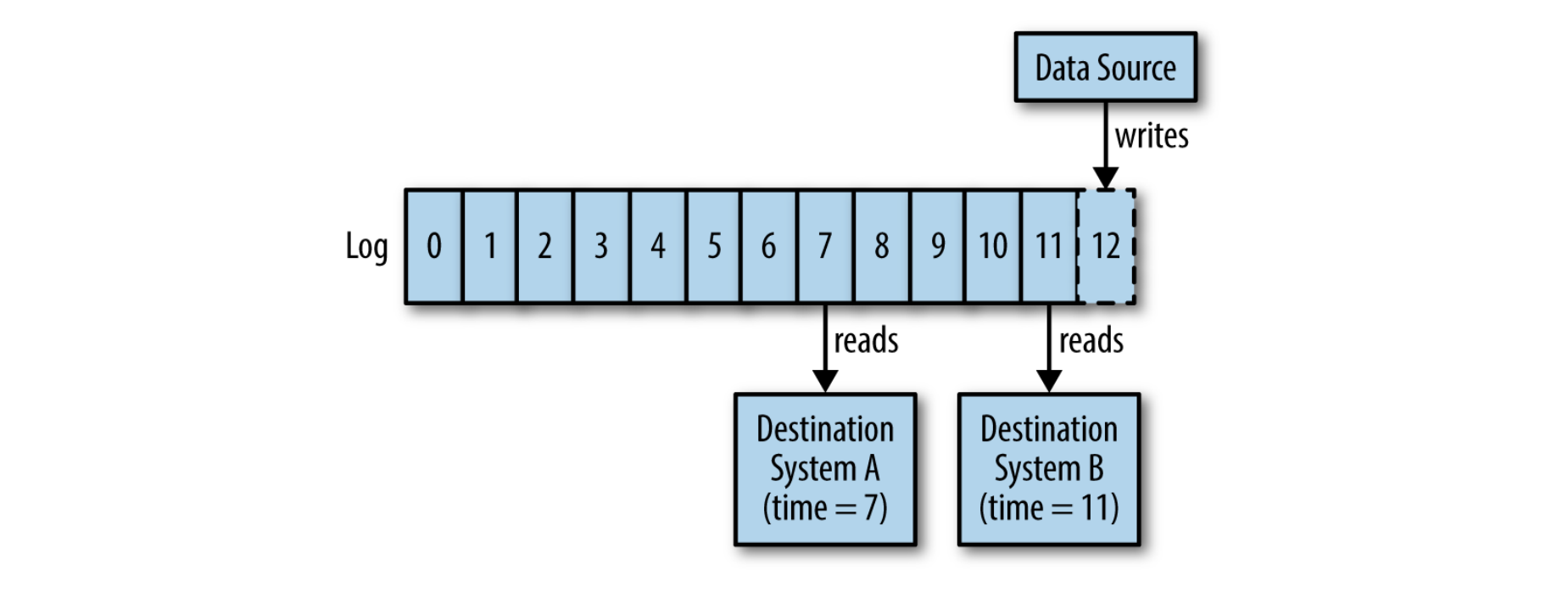
Das Log als Publish-Subscribe-Pattern. Der Publisher fügt seinem Log neue Events hinzu und der Subscriber hält einen Pointer auf seine aktuelle Position um unabhängig Lesen zu können. Entnommen aus [KREP14]
Ein Log kann also asynchrones Verhalten ermöglichen und braucht selbst kein Wissen über existierende Konsumenten, genauso wenig wie der Produzent. Umgekehrt muss der Konsument nicht wissen, wo oder wie das Event erzeugt wurde. Logs sind nicht nur die ideale Datenstruktur um Streams abzubilden, sie liefern auch die im ersten Kapitel beschriebene Isolation von kommunizierenden Systemen.
Architektur
Es muss betont werden, dass die reine Separation von Produzent und Konsument nicht ausreicht. Wie bereits angemerkt ist die Skalierbarkeit der Idee von größter Bedeutung. Die Nutzung eines Logs als universalen Mechanismus der Daten- und Komponentenintegration bleibt nur eine elegante Fantasie, wenn das Log nicht schnell, günstig und skalierbar genug betrieben werden kann um in dieser Domain praktikabel zu sein[KREP14]. Verteilte Logs scheinen auf den ersten Blick eher schwerfällig (Vergleich Blockchain), aber mit einer durchdachten Implementierung, fokussiert auf die Aufzeichnung großer Datenströme, können durchaus beeindruckende Geschwindigkeiten erreicht werden. In Kafka wird dies durch die Partitionierung des Logs umgesetzt:
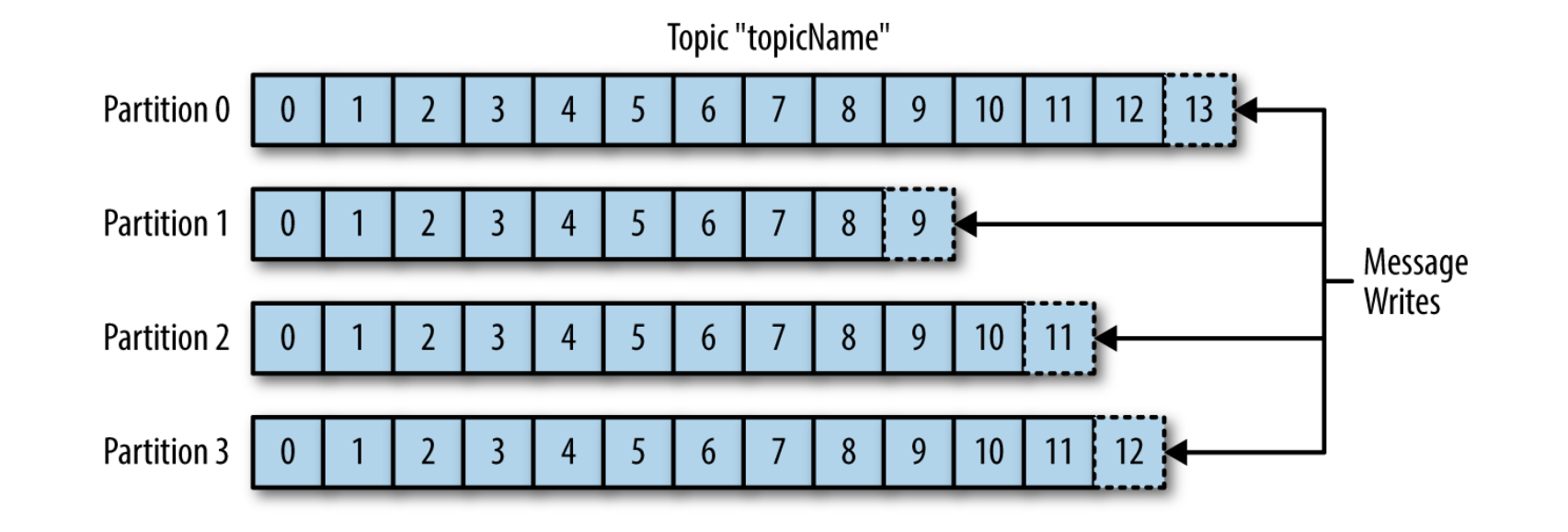
Horizontale Skalierung des Logs durch Partitionierung. Entnommen aus [SHAP17]
Kafka organisiert Events (auch Messages genannt) in Topics. Topics sind vergleichbar mit Tabellen einer Datenbank oder Ordnern in einem Dateisystem. Diese Topics werden nun partitioniert. Jede Partition ist ein eigenes geordnetes Log. Hier ist zu beachten, dass es zwischen einzelnen Partitionen keine globale Ordnung gibt, außer der Produzent würde eine solche Ordnung durch das Hinzufügen entsprechender Daten forcieren, zum Beispiel mit einem Zeitstempel. Dann obliegt dessen Interpretation aber dem Entwickler. Bei der Strukturierung von Topics muss dieser Umstand also berücksichtigt werden. Topics sollten so definiert werden, dass die Reihenfolge von Ereignissen innerhalb eines Topics nicht mit einer absoluten Ordnungsgarantie verknüpft sein muss. Ist dies gefordert, sollte auf Partitionierung verzichtet oder stattdessen analysiert werden, ob der Split auf mehrere Topics, die in sich wieder partitioniert werden könnten, möglich ist. Sind diese Eigenheiten bedacht worden, wächst die Bandbreite linear mit der Größe des Kafka Clusters[KREP14]. Kafka kann Partitionen automatisch über mehrere Server streuen, wodurch ein Topic horizontal skaliert.
Per default bevorzugt ein Kafka-Producer keine Partition und verteilt seine Messages gleichmäßig (Round-Robin) über alle Partitionen eines Topics. Ebenso lesen Kafka-Consumer von allen Partitionen eines Topics und tracken dabei, welche Events sie bereits konsumiert haben, indem sie für jede Partition das sogenannten Offset speichern – eine Metainformation, die kontinuierlich von Kafka mit jeder gespeicherten Nachricht erhöht wird (siehe Integer "time" im Abschnitt Datenfluss). Durch die Vorhaltung des Offsets im ZooKeeper (später genauer erklärt) können Consumer stoppen und neustarten, ohne dass ihr Zustand inkonsistent wird oder das System davon beeinflusst werden würde. Diese Selbstorganisation auf Seite des Consumers erlaubt die Bündelung in Gruppen. Kafka-Consumer können so zusammengefasst werden, dass sie die Verarbeitung von Events eines partitionierten Topics automatisch untereinander aufteilen::
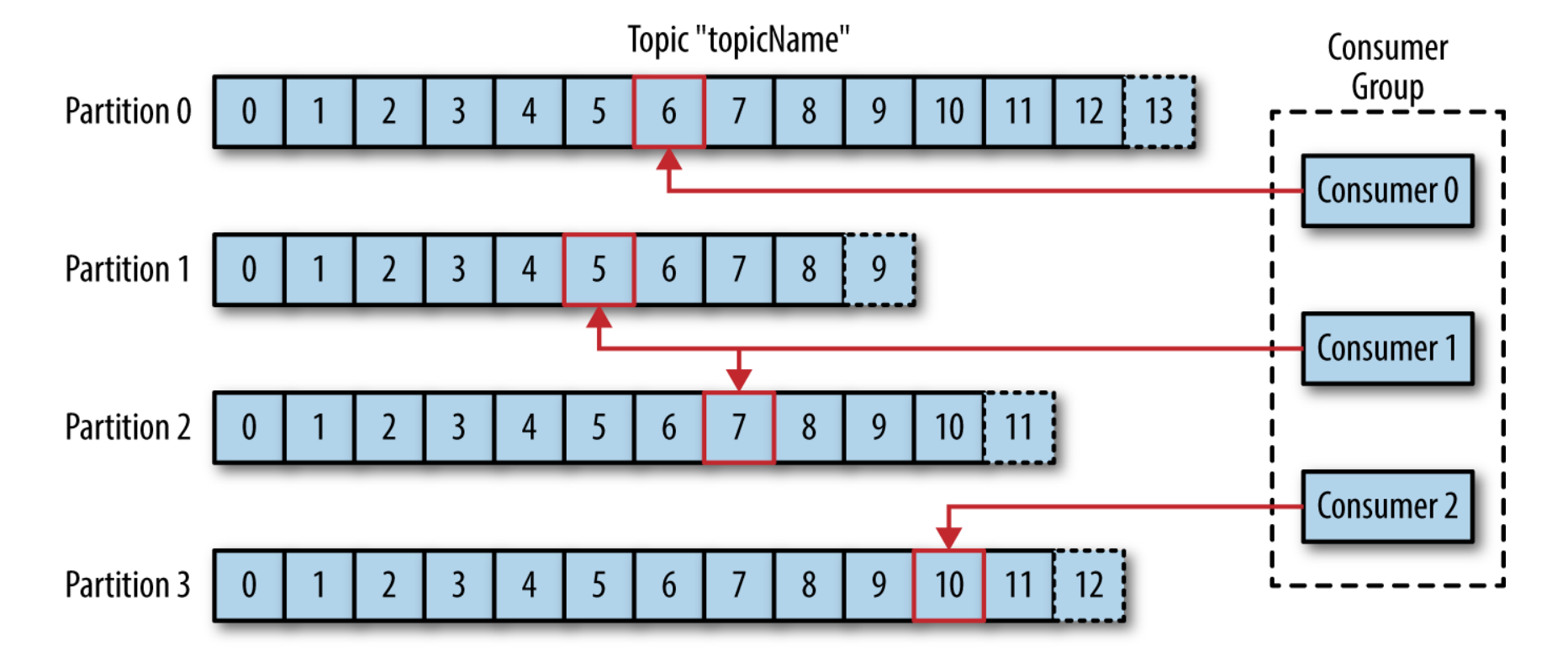
Consumer-Group, die ein partitioniertes Topic verarbeitet. Entnommen aus [SHAP17]
Auf diese Weise kann auch die Verarbeitung eines Stroms horizontal skaliert werden. Zusätzlich erlaubt der Ansatz, dass im Falle des Ausfalls eines Konsumenten die anderen der Gruppe die Verarbeitung der Partitionen eines Topics neu balancieren können um den Ausfall aufzufangen.
Broker und Cluster
Einzelne Kafka-Server werden Broker genannt. Sie empfangen Nachrichten von Produzenten, berechnen Offset-Werte und persistieren Values auf dem Speichermedium. Für Konsumenten stellen sie den Zugriff auf gespeicherte Events bereit. Broker sind in der Lage tausende Partitionen und mehrere Millionen Anfragen pro Sekunde zu managen[SHAP17], natürlich in Abhängigkeit der darunterliegenden Hardware. In der Regel gilt für Kafka aber der Durchsatz der Netzwerkanbindung als obere Leistungsgrenze. Broker sind nach dem Zero-Copy-Paradigma entworfen worden. Es wird also nach Möglichkeit immer versucht, Context-Switches zu vermeiden.
Die Broker selbst sind ebenfalls skalierbar konzipiert. Sie können als Teil eines Clusters auftreten. In einem Cluster wird automatisch ein Broker als Controller gewählt. Er regelt die Verteilung von Partitionen auf die einzelnen Broker und beobachtet, ob alle Broker korrekt arbeiten. Pro Partition gilt ein Broker als Leader. Wird diese Partition mehreren Brokern zugewiesen, wird sie automatisch vom Leader gespiegelt für den Fall eines Ausfalls. Dann wird automatisch ein neuer Leader zugewiesen. Producer und Consumer interagieren immer nur mit dem Leader einer Partition, welcher über die Verarbeitung entscheidet. Das beschriebene Konstrukt ist in nachstehender Grafik visualisiert:
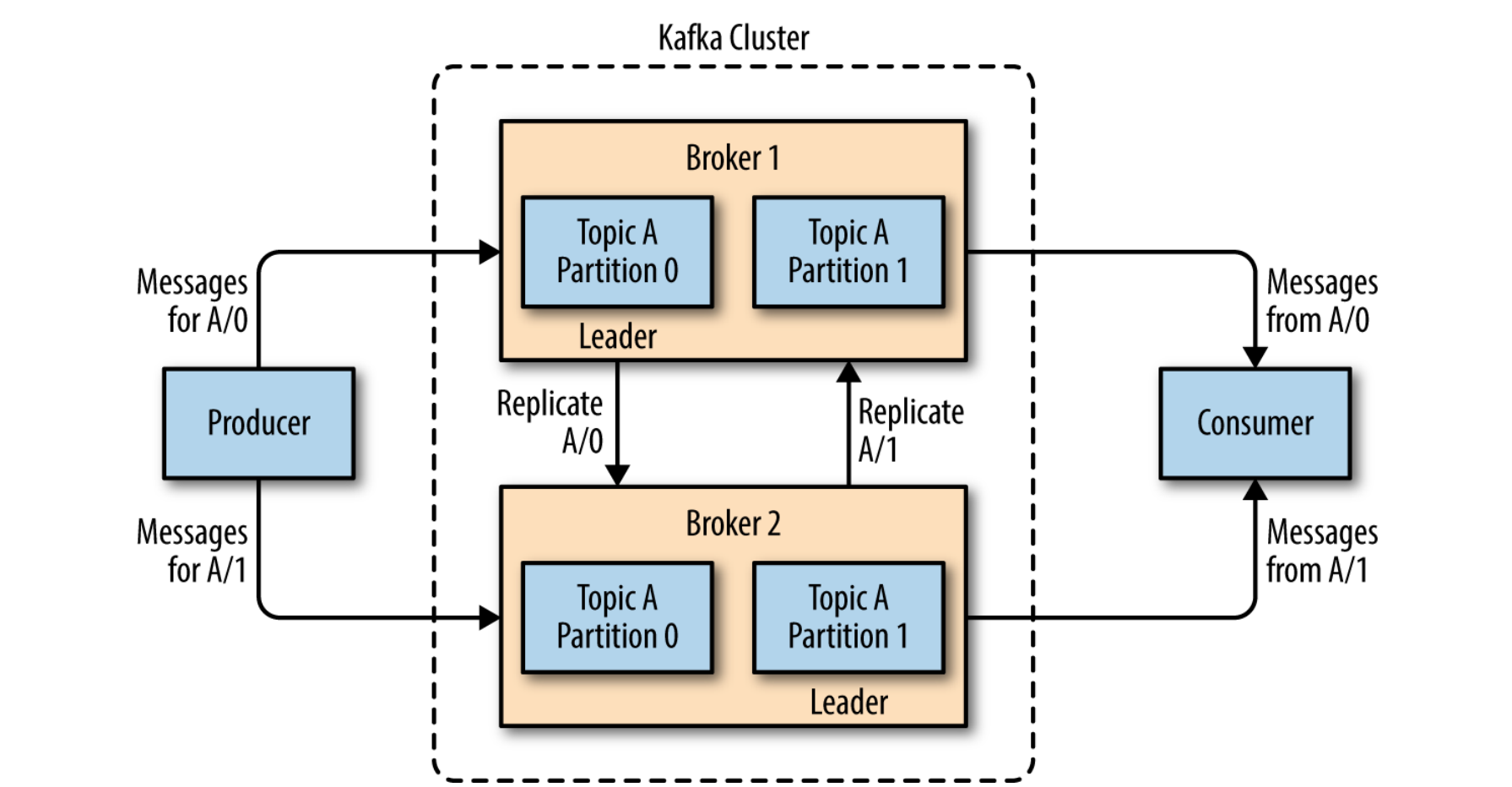
Replikation in einem Broker-Cluster. Entnommen aus [SHAP17]
Dank dieser Architektur ist Kafka beliebig skalierbar und kann dem Anwendungsfall entsprechend erweitert werden. Dabei können kommunizierende Cluster auch auf verschiedenen Rechenzentren verteilt sein. Das System wird als hochperformantes Cluster-Commit-Log verstanden. Im Kern liegt aber immer die simple, oben beschriebene Datenstruktur. Kafkas Stärke ist das um diese Datenstruktur geschaffene Ökosystem. Wenn dessen Komponenten überlegt auf eine geeignete Hardware-Topologie aufgebracht werden, erhält man eine performante und robuste Option für den einfachen Datenaustausch. Es muss allerdings immer bedacht werden, dass es sich hierbei nicht um einen Data Lake handelt. Kafkas Retention-Policy greift die Paradigmen der Streaming Architektur auf und hält Daten nur für eine begrenzte Zeit vor. Sie wird limitiert durch das Alter der Events oder die Größe eines Topics. In der Standardkonfiguration werden Daten nach 7 Tagen fallen gelassen, unabhängig davon ob sie konsumiert wurden oder nicht. Die Retention-Policy kann für jedes Topic individuell festgelegt werden. Hier liegt die wichtige Verknüpfung zu den Anmerkungen des ersten Kapitels. Daten sollten nur so lange gehalten werden, wie sie auch wirklich nützlich sind. Das heißt entweder wurden sie konsumiert, transformiert oder anderweitig persistiert. Grundsätzlich können Daten aber auch dauerhaft in Kafka abgelegt werden um eine volle Historie zu halten, wenn gewünscht und entsprechend konfiguriert. Diese Strategie impliziert den „bad smell“, dass man mit Kafka vermutlich nicht die richtige Technologie für den Anwendungsfall gewählt hat.
Kafka Peripherals
Mit "Kafka" wurde bisher für das einfachere Verständnis im Wesentlichen das Cluster aus Log-Partitionen beschrieben, aber tatsächlich sind für dessen Betrieb weitere Komponenten notwendig.
Apache ZooKeeper - Distributed Configuration Management
Hervorgehoben wurde, dass nahezu alle Komponenten innerhalb und an den Schnittstellen Kafkas verteilt, skalierbar und ausfallsicher konzipiert sind. Diese Fähigkeiten erfordern umfassende Koordination zwischen den einzelnen Elementen. Dazu zählen Producer, Consumer, Partitionen, Broker, Mirror-Dienste, Cluster und Cluster-Verbünde. Kafka greift dazu auf eine weitere Applikation aus dem Apache-Umfeld zurück: ZooKeeper. Dabei handelt sich um einen verteilten Dienst für das Konfigurationsmanagement. ZooKeeper kann als leichtgewichtiges in-memory Dateisystem verstanden werden[KONI16a]. Systeme wie Kafka haben einen besonderen Anspruch an die Verfügbarkeit ihrer Konfiguration. ZooKeeper ist speziell für solche Anwendungsfälle entwickelt worden. Dieses Dateisystem in Form eines über das Netzwerk erreichbaren Storage-Dienstes, wird für die Speicherung von Metainformationen im Größenbereich weniger Kilobytes eingesetzt. Durch das erzwungene Größenlimit und die Vorhaltung im Arbeitsspeicher, sind sehr hohe Austauschgeschwindigkeiten möglich. Kafka-Komponenten teilen sich eine ZooKeeper-Instanz um sich zu koordinieren, ohne dass die gemeinsame Absprache einen nennenswerten Einfluss auf die Gesamtreaktionszeit hat. Sollte diese doch einmal durch Systemerweiterungen signifikant werden, dann kann auch die ZooKeeper-Instanz horizontal skalieren. Dass Hinzufügen weiterer Instanzen genügt bereits um den Flaschenhals zu lösen.
Insbesondere Broker und Consumer interagieren mit ZooKeeper um Informationen zu halten oder auszutauschen[KONI16b]:
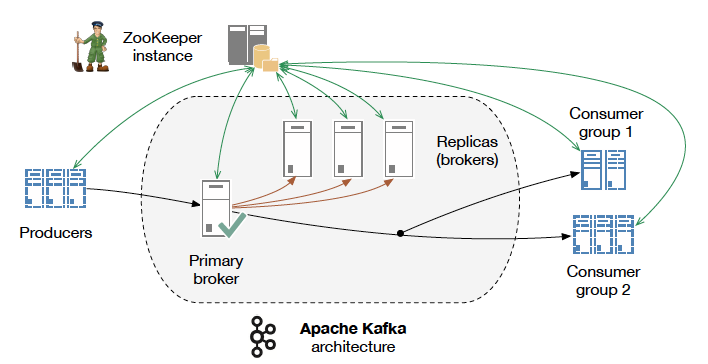
ZooKeeper im Kafka-Verbund. Quelle: https://content.pivotal.io/blog/understanding-when-to-use-rabbitmq-or-apache-kafka
Broker:
- state - ZooKeeper speichert den aktuellen Zustand jedes Brokers basierend auf seinen heartbeat-Requests.
- quotas – Brokern kann vorgeschrieben werden, welche Consumer und Producer einem Volumenlimit pro Topic unterliegen. Äquivalent zu einer R/W-Berechtigung.
- replicas – Es wird festgehalten, welche Replikate aktuell für welches Topic online und synchron sind. Fällt ein Replikat aus, wird die Information aktualisiert. Sollte das ausgefallene Replikat ein Leader gewesen sein, wird ein neuer Leader ausgewählt.
- nodes and topics registry – Speichert, welche Broker aktuell existieren und für welche Topics/Partitionen sie zuständig sind. Diese Information enthält nur Nodes, die auch eine offene Session mit dem ZooKeeper halten. Regelt gleichzeitig Cluster-Membership. Producer können ihr Write-Target ermitteln.
Consumer:
- offset – Entspricht dem bereits erwähnten Lesepunkt auf einem Eventstrom. Da der Wert im ZooKeeper gehalten wird, können Consumer ausfallsicherer betrieben werden. Zugleich ist so an zentraler Stelle der Status aller Consumer abrufbar.
- registry – Übersicht über alle Consumer, die aktuelle eine offene Session mit ZooKeeper halten partitions registry – Für Koordination innerhalb von Consumer-Gruppen.
ZooKeeper muss nicht speziell für Kafka konfiguriert werden. Es genügt eine Instanz zu starten und Kafka einen Zugang über das Netzwerk zu garantieren. Das Anlegen der nötigen Datenstrukturen und die Absprache zwischen den Komponenten erfolgt vollautomatisch. Im Normalbetrieb sollte man sich nicht näher mit ZooKeeper beschäftigen müssen, da Anpassungen über die Kafka-Administrationswerkzeuge zu ZooKeeper propagieren. Um zu verstehen, wie Kafka im Hintergrund arbeitet und seine Skalierbarkeit realisiert, wurde hier aber dennoch kurz darauf eingegangen.
(De-)Serialisierung
Nachdem nun ein Verständnis aufgebaut wurde, wie die Grundkomponenten des Kafka-Systems zusammenarbeiten und gemeinsam skalieren, soll jetzt näher auf die über Kafka ausgetauschten Messages eingegangen werden, die den eigentlichen Eventstream bilden. Grundsätzlich ist Kafka gegenüber dem Inhalt von Events ohne Wissen oder Bedürfnisse. Message-Keys und -Values sind einfache Bytefolgen. Dieser Ansatz scheint auf den ersten Blick eher hinderlich. In der Regel haben die ausgetauschten Informationen Struktur. Deshalb verlangen Producer und Consumer immer auch Serializer und werden bereits mit verschiedenen Lösungen ausgeliefert. Typische Einsätze sind die Serialisierung von Arrays, Strings usw., also übliche Datentypen. Darüber hinaus können auch eigene Serializer implementiert und genutzt werden um komplexere Objekte über Kafka auszutauschen. JSON ist dabei ebenso möglich. Diese klassischen (De-)Serialisierungsverfahren haben aber im Kafka Kontext zwei Nachteile[CONF18]:
- Overhead: Das Schema und die Bezeichner von Datenfeldern werden immer mit in die Nachricht eingebracht, obwohl diese Information normalerweise in einer Schema-Version identisch bleibt. Es macht also eigentlich keinen Sinn, diese Strukturdaten mit dem Payload zu persistieren. Das Ergebnis ist nur eine Zusatzbelastung für das Gesamtsystem, gerade gemessen an Kafkas typischen BigData-Szenarien.
- Konsumenten verstehen Produzenten unter Umständen nicht: Die genannten Strukturen können sich verändern. Datenfelder könnten hinzukommen oder entfernt werden. Dies ist insbesondere ein Problem für die Entkopplung von über Kafka verknüpften Komponenten. Wenn die beteiligten Entwickler kommunizierte Datenstrukturen beliebig verändern können, ist die Auswirkung nicht vorhersagbar.
Apache Avro + Confluent Schema Registry
Um diese Probleme zu lösen, nutzt Kafka die Kombination zweier weiterer Systeme: Apache Avro und die Confluent Schema Registry. Avro wird zur Beschreibung von Objekten eingesetzt. Der Syntax ist zu JSON identisch. Der wichtige Unterschied liegt aber bei dem Speicherfootprint während der Transmission, wie nachstehende Grafik darstellt:
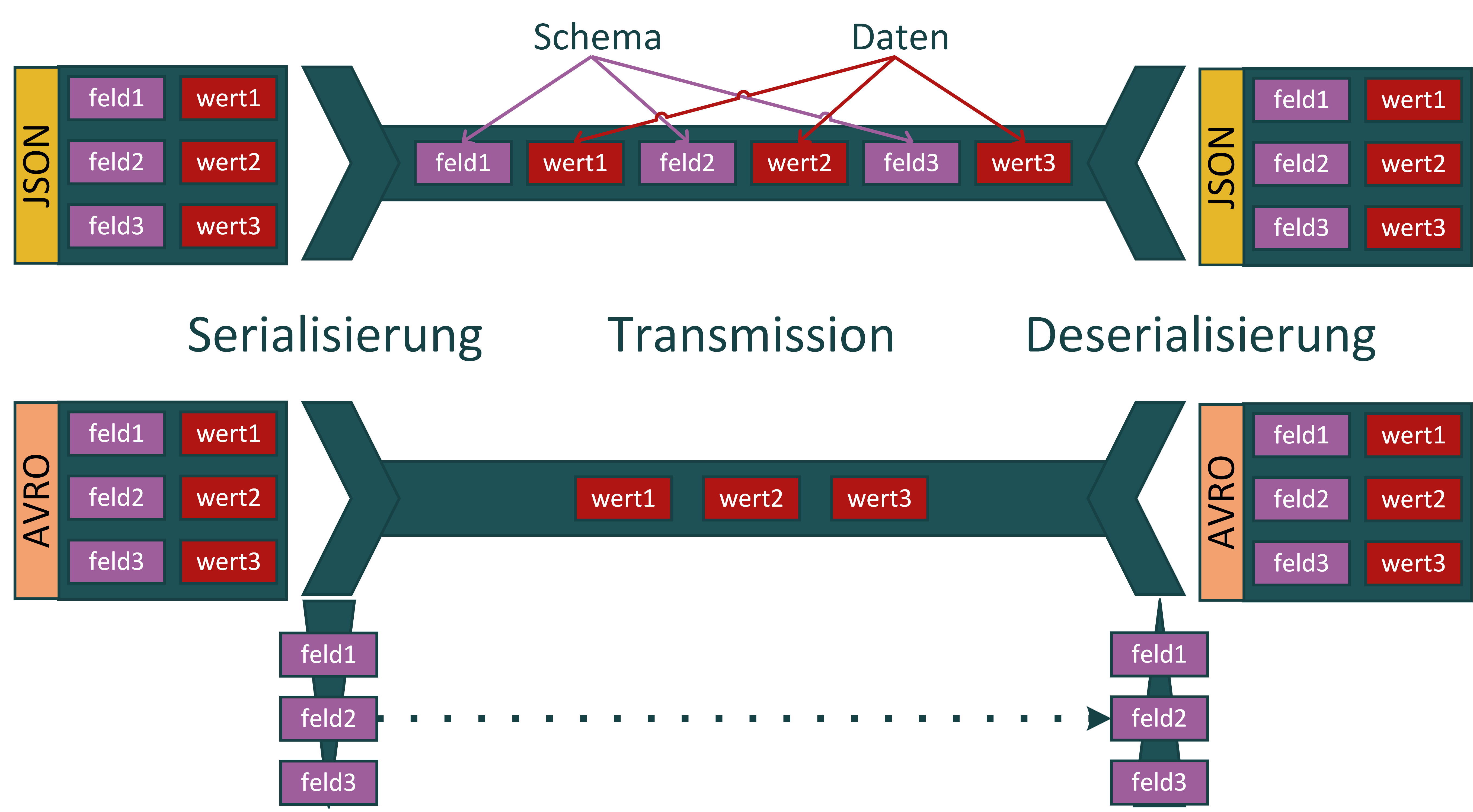
Eigene Grafik.
Avro trennt das Datenschema vom Payload. Während der Transmission oder Persistierung wird es also nicht abgebildet und muss zum Lesen der Daten bekannt sein und wieder hinzugefügt werden. Produzent und Konsument müssten sich dementsprechend auf ein Schema für die Daten, die sie austauschen, vorab einigen. Dies widerspricht dem Entkopplungsgedanken, da sich die beiden Parteien in Kafka nicht explizit kennen. Deshalb tritt die speziell für diesen Fall entwickelte Confluent Schema Registry als Drittpartei auf. Die Schema Registry dienst als Austauschdienst für Schemata, die mit Kafka Topics verknüpft sind. Der Ablauf besteht aus nachstehenden Schritten:
- Der Produzent prüft, ob sein aktuelles Schema in der Registry verfügbar ist. Wenn nicht, registriert er es.
- Die Schema Registry prüft, ob das Schema mit dem eventuell bereits bekannten übereinstimmt, oder eine valide Evolution davon darstellt (Anmerkung: Mehr zur Schema Evolution im nächsten Abschnitt). Wenn nicht, wird der Vorgang abgebrochen und der Produzent informiert, damit dieser eine Serialisierungs-Exception wirft.
- Wenn das Schema als valide akzeptiert wurde und alle Prüfungen erfolgreich durchlaufen sind, sendet der Produzent seine Message an das Topic im Kafka Broker, allerdings erweitert um eine Referenz auf das von ihm verwendete Schema. Diese Referenz ist die ID des in der Registry gespeicherten Schemas, welches als mit der Message kompatibel anerkannt wurde.
Der Konsument der Nachricht kann nun nach folgendem Prinzip die Nachricht rekonstruieren: 4. Der Konsument erreicht mit seinem Offset die neue Nachricht und liest diese. 5. Die vom Produzenten verwendete Schema ID wird extrahiert. Wenn die ID nicht bekannt ist, wird das dazugehörige Schema bei der Schema Registry angefragt. 6. Die Schema Registry stellt das passende Schema bereit. Dies wird im lokalen Cache hinterlegt und die Nachricht wird mit Hilfe des Schemas deserialisiert.
Der Vorgang ist in folgender Grafik visualisiert:
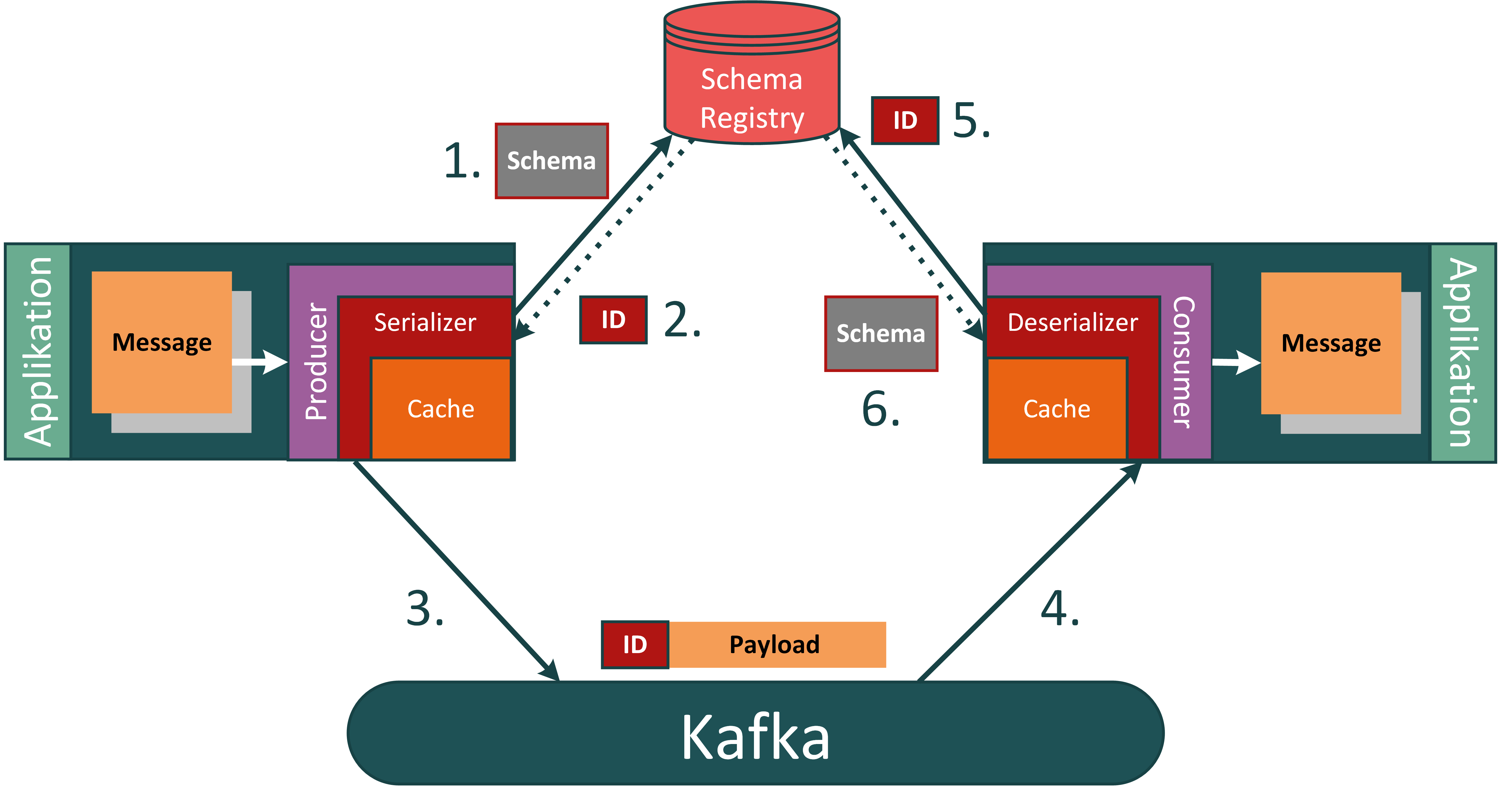
Eigene Grafik.
Dieser Ablauf erlaubt die effizientere Übertragung und Speicherung über Kafka. Produzent und Konsument können sich in ihrer Kommunikation über ein Topic aber weiterhin verstehen und ihre Entkopplung bleibt erhalten. Ein weiterer Vorteil ergibt sich durch die Schema Registry: Schema Evolution[CONF18].
Schema Evolution
Wie im ersten Kapitel dargestellt, sind BigData-Infrastrukturen schnelllebig. Ihre Komponenten verändern sich, genauso wie ihre Schnittstellen. Dies stellt bei einer direkt vernetzten Architektur ein großes Problem für die Erweiterbarkeit dar und selbst mit Kafka als Zwischenschicht muss der Konsument noch immer so entworfen sein, dass er die Messages, die er empfängt, auch verarbeiten kann. Wenn also Datenfelder zu einer Kommunikation hinzugefügt werden oder wegfallen, würde der Konsument sie nicht mehr fehlerfrei parsen können. Andersrum könnte ein Produzent keine Messages absetzen, wenn seine Konsumenten ein neueres Schema erwarten, als er selbst nutzt. Die Schema Registry verhindert dies. Weiterhin müssten also alle Schnittstellen von allen Parteien angepasst werden – ein Problem. Um auch diesen Sachverhalt zu lösen, wurde die Schema Registry mit Unterstützung für Avro Schema Evolution entworfen[CONF18]. Mit folgendem Beispiel soll das Prinzip anschaulich gemacht werden. Avro Schemata werden in JSON festgehalten und können Objekte sehr einfach definieren. Gegeben ist ein "fahrzeug" beschrieben durch die Felder "modell" und "farbe" mit den Datentypen "string" und "int". Kafkas Producer/Consumer-Libraries können diesen Avro String nutzen um den Payload einer Kafka Message zu (de-)serialisieren und die Information mit der Struktur eines Plain Old Java Objects zu knüpfen.
{"namespace": "beispiel.fahrzeug",
"version":"v1",
"type": "record",
"name": "auto",
"fields": [
{"name": "modell", "type": "string"},
{"name": "hubraum", "type": "int"}
]
}
Dieses Schema soll sich nun verändern, wie es für einen typischen Anwendungsfall üblich ist. Hardgecodete Parser hätten damit ein Problem, wenn die Kompatibilität nicht auf andere Art sichergestellt wird und Kafka kennt dafür drei Strategien: "Backward Compatibility", "Forward Compatibility" und "Full Compatibility".
Backward Compatibility bedeutet, dass Daten, die mit einem älteren Schema erzeugt wurden, mit einem neueren Schema noch immer gelesen werden können. Das heißt, dass zum Beispiel eine neue Systemkomponente, welche zusätzlich die Farbe eines Autos benötigt, die produzierten Messages einer alten Komponente, die keine Autofarben kennt, lesen und verarbeiten kann. Mit Backward Compatibility ist also auch sichergestellt, dass das neueste Schema alle zuvor persistierten Daten ohne Parserfehler verarbeitet. Nachstehendes Beispiel wurde um das Feld "farbe" erweitert.
{"namespace": "beispiel.fahrzeug",
"version":"v2",
"type": "record",
"name": "auto",
"fields": [
{"name": "modell", "type": "string"},
{"name": "hubraum", "type": "int"},
{"name": "farbe", "type": "string", "default": "schwarz"}
]
}
Wichtig ist der Standardfarbwert "schwarz", da er erst die Rückwärtskompatibilität ermöglicht (Anmerkung: Der semantische Sinn sei dabei für die Anschaulichkeit des Beispiels ignoriert). Wird eine alte Message, die das Feld "farbe" nicht enthält, mit dem neuen Schema deserialisiert, füllt der Avro Deserializer das Feld im POJO automatisch mit dem gegebenen Wert. Aus Sicht der dem Deserializer übergeordneten Applikation ist das Objekt dann entsprechend seiner programmierten Erwartung vollständig und die Programmlogik kann damit arbeiten, obwohl der Produzent der Message nie explizit für die Zusammenarbeit mit der neuen Komponente entwickelt wurde. An diesem Punkt wird die Mächtigkeit der Schema Evolution deutlich. Die Schema Registry ist in der Lage, neue Schemata auf ihre Evolutionsfähigkeit zu prüfen und lässt sie nur zu, wenn sie entsprechend der gewählten Kompatibilitätsstrategie gültig sind. Dabei werden auch Datentypen und deren Konvertierbarkeit (Casting) geprüft. Hätte "farbe" keinen Standardwert oder einen numerischen Typ, wäre das neue Schema abgelehnt worden.
Forward Compatibility garantiert demgegenüber, dass Daten, die ein neues Schema erzeugt, von alten Schemata weiterhin verstanden werden. Enthält das neue Schema bisher unbekannte Felder, werden diese vom älteren Consumer einfach ignoriert. Forward Compatibility ist aber auch dann nützlich, wenn die neue datenproduzierende Systemkomponente alte Datenfelder nicht mehr befüllt. Werden diese aus dem Schema entfernt, können ältere Konsumenten die neuen Messages nicht mehr lesen, da keine Information zum Inhalt der fehlenden Felder existiert. Sollte das "modell" in einer neuen Version keine Rolle mehr spielen, aber dennoch Forward Compatibility gegeben sein, müsste ein Standardwert hinterlegt werden, also zum Beispiel "default":"generisches Automodell", damit das Objekt aus Sicht alter Applikationen weiterhin vollständig ist.
{"namespace": "beispiel.fahrzeug",
"version":"v3",
"type": "record",
"name": "auto",
"fields": [
{"name": "modell", "type": "string", "default": "generisches Automodell"},
{"name": "hubraum", "type": "int"},
{"name": "farbe", "type": "string", "default": "schwarz"}
]
}
Full Compatibility ist dann die Kombination aus den beiden vorgenannten Strategien und stellt sowohl Forward, als auch Backward Compatibility sicher. Als höchste Kompatibilitätsstufe erfordert sie auch die größte Aufmerksamkeit des Entwicklers. Es sollten einige Best Practices beachtet werden, damit ordnungsgemäße Schema Evolution gewährleistet ist:
- Es sollten immer Standardwerte angegeben werden.
- Datentypen sollten nicht verändert werden.
- Felder sollten nicht umbenannt werden. Ist dies doch zwingend nötig, existieren auch Aliasfunktionen im Avro Standard.
Kafka Connect
Augenscheinlich handelt es sich beim Kafka Ökosystem um einen verhältnismäßig komplexen Verbund von wichtigen Komponenten. Die Eigenheiten dieser Komponenten sind beschrieben worden und somit sollte der Eindruck entstanden sein, dass die Integration bestehender Systeme mit Kafka unter Beachtung all dieser Eigenheiten eine Hürde für den Entwickler darstellen kann. Der Sinn Kafkas ist aber der möglichst einfache Austausch von Informationen zwischen beliebigen Parteien. Damit dieser Designanspruch weiterhin erhalten bleiben kann, wurde das Kafka Connect Framework mit in die Plattform aufgenommen.
Mit Kafka Connect wird ein System geliefert, welches den einfachen Import/Export von Informationen aus anderen Systemen garantiert. Der Grundgedanke ist, dass bestimmte Aufgaben immer die gleichen Producer und Consumer benötigen. Sollen beispielsweise Events aus einem Topic in eine Datei geschrieben werden, ist der Code zur Realisierung dieses Consumers wie Boilerplate zu verstehen. Der Code würde für alle Anwendungsfälle nahezu identisch aussehen und sich lediglich durch Konfigurationsmerkmale (z.B. der Dateiname) unterscheiden. Dies gilt natürlich auch für das Lesen aus einer Datei. Kafka Connect stellt für solche repetitiven Entwicklungsaufgaben eine Kombination aus Producer und Consumer bereit, die sogenannten Connector. Sie müssen nur über eine Konfigurationsdatei nötige Einstellungen erhalten und bilden dann die Brücke zwischen Kafka und anderen Systemen. Also anstatt händisch eine Applikation zu entwickeln, die den Consumer/Producer Code enthält und FileReader/Writer anspricht um das Dateisystem einzubeziehen, kann auch einfach ein File Connector gestartet werden, dem mitgeteilt wird, welches Topic er in welche Datei schreiben soll – oder andersherum. Diese Vereinfachung erlaubt es, deutlich schneller mit Kafka in Kontakt zu treten. Es sollte also immer erst geprüft werden, ob für den vorliegenden Anwendungsfall bereits ein fertiger Connector existiert. Da diese auch dem Open Source Prinzip folgen, werden von der Kafka Community dauerhaft neue Connectoren angeboten, zusätzlich zu den bereits enthaltenen. So sind auch sehr komplexe Anbindungen äußerst einfach realisierbar. Beispielsweise wurden Connector entwickelt, die relationale Datenbanksysteme an Kafka anschließen können oder sogar Twitter Feeds einbinden. Teilweise werden diese Community Lösungen auch durch Confluent – dem Unternehmen hinter Kafka - zertifiziert und dann offiziell unterstützt. Die nachstehende Grafik gibt eine Übersicht über aktuell verfügbare Connector Projekte.
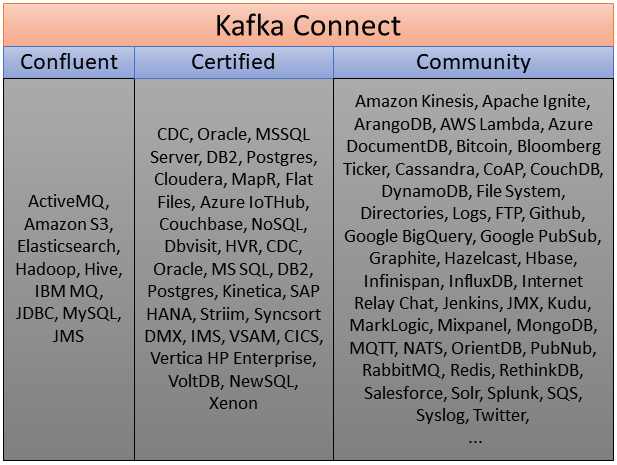
Eigene Grafik.
Diese Connector arbeiten als Zwischenschicht zwischen Kafka und dem externen System. Sie sind für genau einen Verbindungsfall entwickelt. Ein RDBMS Connector wäre also auch nur für diesen Einsatz spezialisiert und kann für keine andere Verbindung eingesetzt werden. Der Vorteil der Spezialisierung ergibt sich durch das im Connector abgebildete Domainwissen bezüglich des Verbundsystems. Würde ein SQL Update im RDBMS ausgeführt werden, führt der Connector automatisch das gleiche Update im korrespondierenden Kafka Topic aus. Eine derart komfortable Integration erfordert natürlich einen hohen Entwicklungsaufwand im Connector. Ist dieser aber einmal implementiert worden, kann er mit der Community geshared werden. Nach diesem Prinzip werden immer mehr Systeme anbindbar und der Nutzer profitiert davon, dass mit Kafka wiederkehrende Verbindungsprobleme einfacher zu lösen sind.
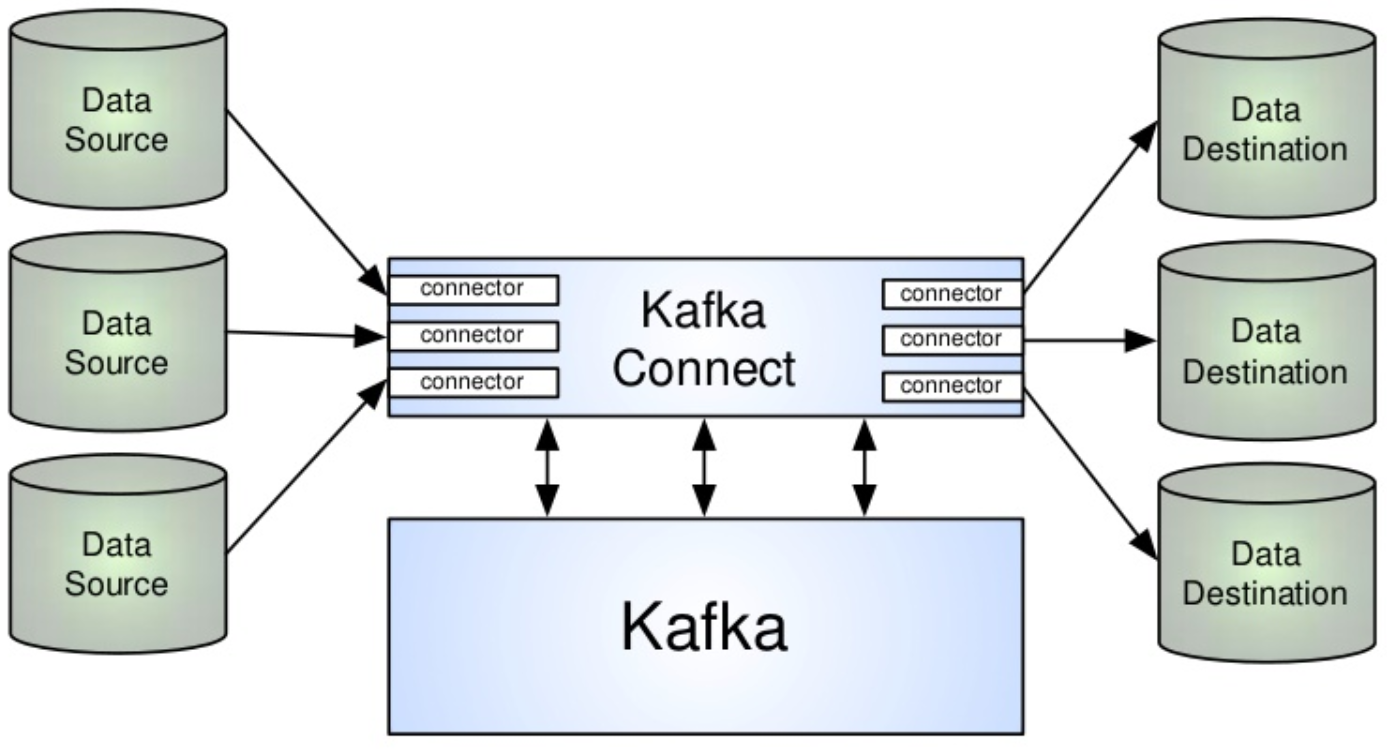
Connect im Kafka Verbund. Quelle: https://de.slideshare.net/KaufmanNg/data-pipelines-with-kafka-connect
Stream Processing
Ein wichtiger Bestandteil der informationszentrischen Streaming Architektur ist neben dem reinen Informationsaustausch auch das eigentliche Arbeiten mit der Information. Dies wird im Falle strömender Daten als Stream Processing bezeichnet. Das Konzept ist aber nicht unterschiedlich zu typischer Datenverarbeitung mit Eingabe, Verarbeitung und Ausgabe. In diesem Kontext redet man vom Konsumieren, Transformieren und Produzieren (ETL: Extract, Transform, Load). Lediglich der Aspekt der Zeitinformation einer potentiell unendlichen Datenmenge muss bedacht werden.
Kafka beherrscht drei Ansätze zur Transformation von Streams.
Grundsätzlich kann eine Applikation einfach als Producer und Consumer gleichzeitig auftreten und im Zwischenschritt eine Transformation auf einem Kafka Eventfluss ausführen. Tatsächlich wäre dieser Ansatz nicht unüblich und er erlaubt auch das größte Maß an Flexibilität. Um aber typische Anwendungsfälle mit weniger Code abbilden zu können, wurden spezialisierte Lösungen in Kafka integriert.
Kafka Streams API
Die Streams API liefert typische Funktionen, die häufig auf Eventströmen angewendet werden. Dazu zählen Aggregationen, Windowing und Filteroperationen. Diese sind in einer eigenen Domain Specific Language definiert und arbeiten auf den Datentypen KStream und KTable, die einen schnellen Zugang zu Streams aus Kafka ermöglichen. Das nachstehende Beispiel zeigt den Syntax, der nötig ist, um die Nachrichten eines Topics in Großbuchstaben zu "transformieren".
// Daten deserialisieren und aus Kafka lesen
KStream<byte[], String> text = builder.stream("topic", Consumed.with(Serdes.ByteArray(), Serdes.String()));
// Daten transformieren
KStream<byte[], String> textGross= text.mapValues(String::toUpperCase));
// Daten in anderes Topic zurueckschreiben
textGross.to("topicGross", Produced.with(Serdes.ByteArray(), Serdes.String()));
Das Besondere an der Kafka Streams API ist ihre Architektur. Es wurde darauf verzichtet, die Streamtransformation in das Kafka Cluster aufzunehmen. Stattdessen werden sie von einfachen Java Applikationen abgebildet, die, wie jede andere Java Applikation, gepackt und deployed werden können. Die dafür genutzte Streamsbibliothek ist mit allen vorgestellten Kafka Komponenten integriert und unterliegt den gleichen Vorzügen. Da eine Streamtransformation auf diese Weise die Rolle eines Consumers einnimmt, kann ZooKeeper das Grouping steuern. So werden alle über die Streams API definierten Applikationen implizit beliebig skalierbar und erhalten zusätzlich auch ein Loadbalancing. Ist eine Transformation sehr raum- oder zeitkomplex, kann sie einfach ein weiteres Mal gestartet werden. Über ZooKeeper werden beide Instanzen automatisch in eine Consumergroup aufgenommen und die zu verarbeitenden Daten werden zwischen den Instanzen geteilt. Zeitgleich wird durch den ZooKeeper Heartbeatcheck Ausfallsicherheit und Recoveryfähigkeit erlaubt. Für den Entwickler ist es dann nicht mehr gefordert, Parallelisierung und Clusterorganisation explizit in den Softwareentwurf aufzunehmen. Das Kafka Ökosystem erledigt diesen diffizilen Schritt selbstständig.
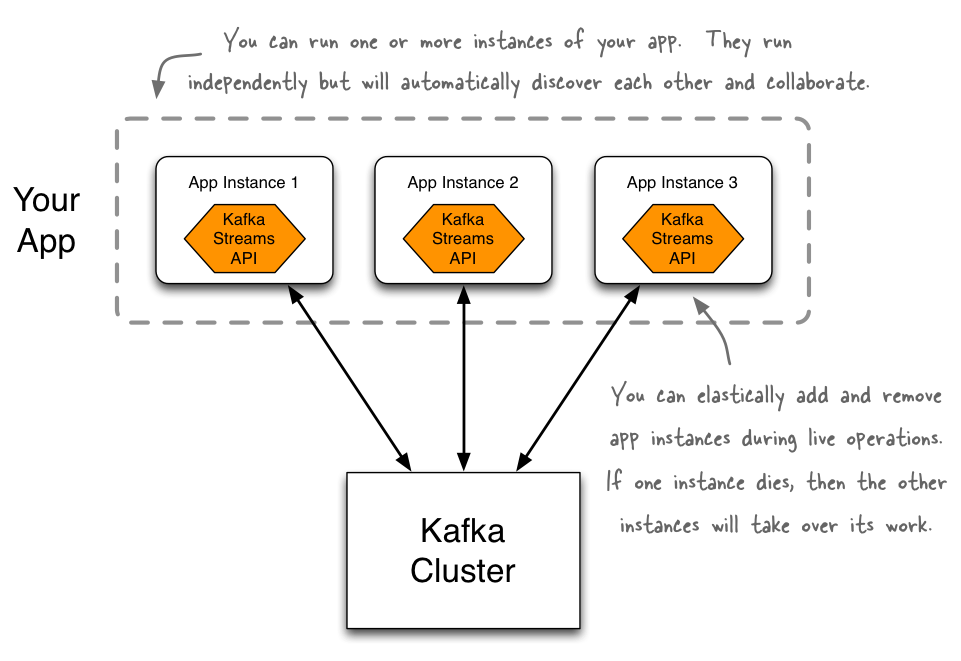
Streams API Architektur. Quelle: https://docs.confluent.io/current/streams/introduction.html
Die beiden Datentypen KStream und KTable spiegeln zwei unterschiedliche Betrachtungen eines Eventstroms wieder und erlauben verschiedene Einblicke. An diesem Punkt ist es förderlich, die Dualität von Strömen und Tabellen zu verstehen. Bisher wurden Eventfolgen als die Zukunft der skalierbaren Datenverarbeitung beschrieben und Tabellen – mit Batchprocessing assoziiert – als zu ersetzen proklamiert. Es sollte betont werden, dass Events aus den im ersten Abschnitt genannten Gründen ein wichtiger Schritt zu einer besseren Architektur repräsentieren, Tabellen aber weiterhin ihre anschauliche Daseinsberechtigung haben. Gegen sie wurde lediglich als zu persistierende Datenstruktur argumentiert.
Streams und Tabellen stehen keineswegs im Gegensatz zueinander und tatsächlich verbindet sie eine gemeinsame Dualität. Eine Folge von Ereignissen kann als Veränderungshistorie einer Tabelle verstanden werden, sodass jedes Event eine Zustandsveränderung der Tabelle darstellt. Wird also der Stream von Anfang bis Ende "abgespielt" und akkumuliert, erhält man den aktuellen Zustand einer Tabelle. In umgekehrter Interpretation ist eine Tabelle die Momentanbeobachtung eines Streams und seiner temporal komprimierten Vergangenheit:
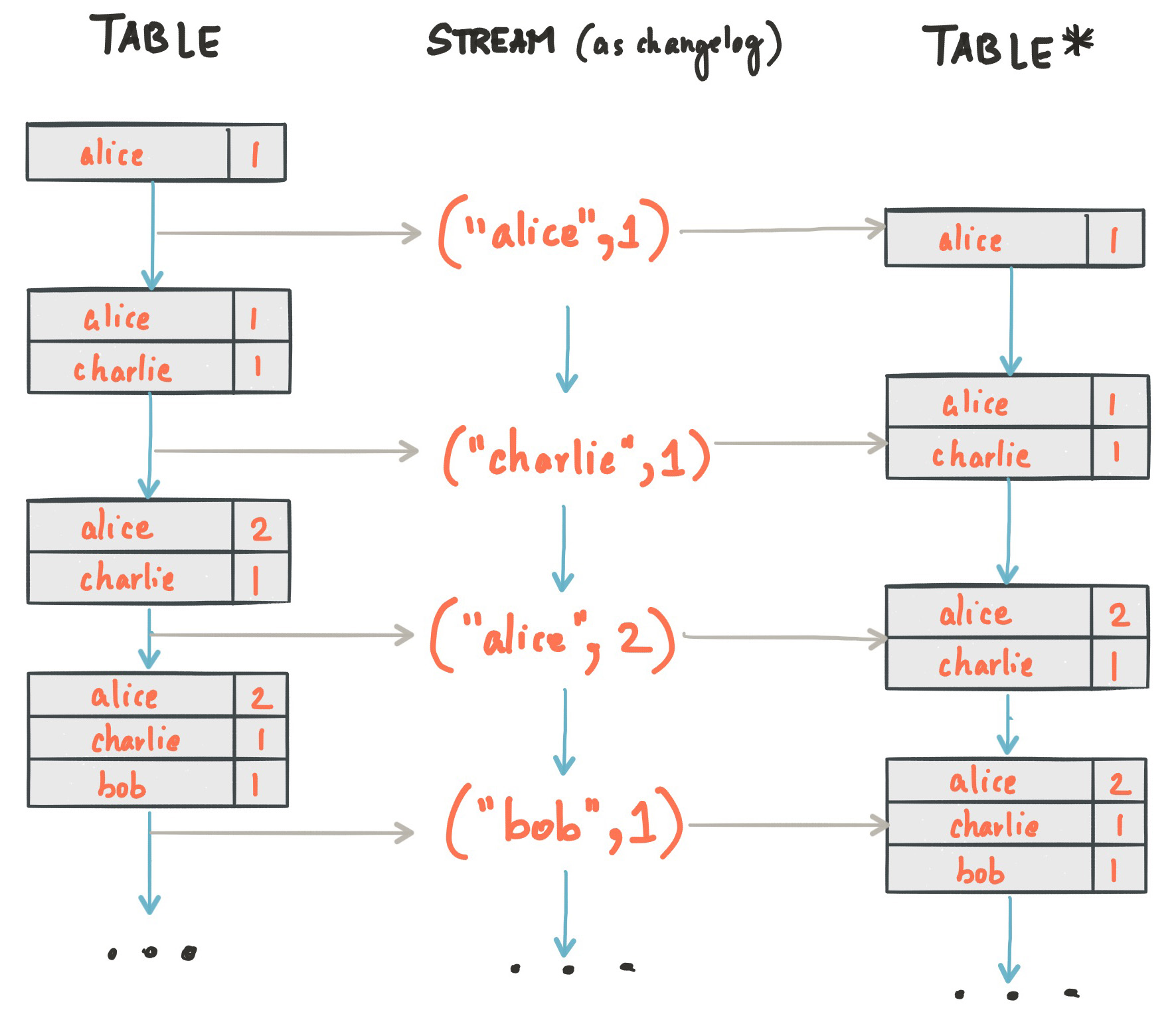
Stream-Table-Dualität. Quelle: https://docs.confluent.io/current/streams/concepts.html#streams-concepts-kstream
KStream und KTable stehen für genau diese beiden Sichtweisen, also einen Eventstrom und dessen Akkumulation. Es obliegt dem Nutzer sich für eine Variante zu entscheiden. Intuitiv kann eine KTable die Transformation unter Umständen einfacher machen. Der konkrete Anwendungsfall sollte die Wahl bestimmen.
KSQL
Die dritte und neueste Möglichkeit zum Interagieren mit Kafkas Streams ist KSQL Die Grundidee ist, eine Abstraktionsschicht auf Kafka aufzubringen, die sich nach außen verhält wie ein regulärer SQL-Server. Der Unterschied liegt natürlich in der strömenden Datenbasis. Diese erlaubt Ansichten in Tabellenform und zusätzlich kontinuierliche Window-Abfragen. Es wird also auch in KSQL mit den beiden im vorherigen Abschnitt genannten Sichtweisen auf Informationsflüsse gearbeitet. Statt KStream- und KTable-Objekten kommen STREAM- und TABLE-Views zum Einsatz. Auf ihnen können im SQL-Syntax aus RDMS bekannte Queries ausgeführt werden.
Um KSQL nutzen zu können, ist der KSQL Server nötig. Er ist ein weiteres, skalierbareres Cluster, welches mit Kafka verbunden wird und die KSQL-Abfragen ausführt. Fällt ein KSQL-Server Node aus, wird seine zu verrichtende Arbeit automatisch auf die verbleibenden Nodes neu verteilt. Nodes können dementsprechend dynamisch hinzugefügt oder entfernt werden:
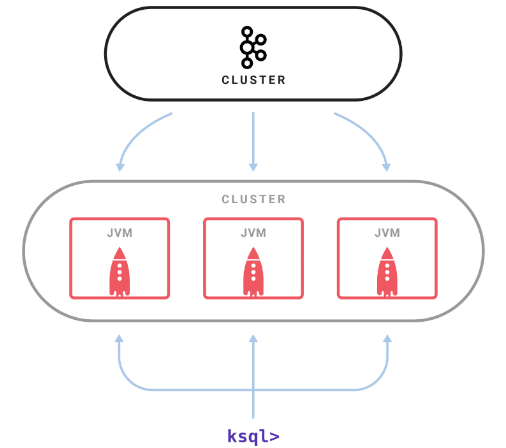
KSQL-Architektur. Quelle: https://www.confluent.io/wp-content/uploads/ksql_cluster-min.png
Das eigentliche Userinterface wird durch die KSQL-CLI gebildet. Für den Nutzer verhält sie sich wie andere SQL-CLIs. Sie übersetzt die eingegebenen Anweisungen in REST-Calls an die API des KSQL-Clusters. Darüber hinaus können laufende, kontinuierliche Queries administriert werden.
Gegenüber der Streams API ist der Zugang zu den in Kafka persistierten Events äußerst niederschwellig. Um alle Ereignisse eines Streams zu erhalten, die eine Bedingung erfüllen, genügt der nachstehende, simple Befehl.
SELECT * FROM kafka-topic WHERE memberfield > 0.8;
Mit KSQL sind dann keine Programmierkenntnisse mehr nötig. Solange ein grundlegendes Verständnis von Abfragesprachen vorhanden ist, kann mit Kafka gearbeitet werden. Zeitgleich sind diese Queries aber durch ein möglicherweise hochskaliertes Cluster gestützt. Sehr umfangreiche oder komplexe Statements werden performant ausgeführt, ohne dass der Nutzer sich explizit um SQL-Tuning kümmern müsste.
Ein weiterer, nicht sofort offensichtlicher Aspekt ist die indirekte Anbindung an Kafka Connect. Werden beispielsweise durch einen entsprechenden Connector Twitterfeeds in Kafka eingeleitet, kann mit KSQL auf diesen Feeds gearbeitet werden. Die Integration der Komponenten erlaubt also das SQL-artige Abfragen von Informationspools, die anderweitig nicht auf diesem Niveau durchsuchbar wären.
Zusammenfassend können die drei Varianten des Stream Processings in Kafka folgendermaßen eingeteilt werden:
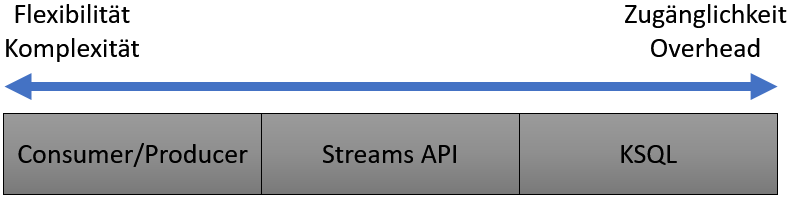
Eigene Grafik.
Die größten Freiheiten erlaubt eine Kombination aus Consumer und Producer. In diesem Fall findet kein Eingriff durch Kafka-Tools statt und der Entwickler hat die freie Entscheidung, wie mit dem Datenstrom umzugehen ist. Hier liegt aber auch der größte Aufwand bei der Verwendung. Es ist fundiertes Wissen der Architektur des Clusters mit seinen Partitionen und Log-Offsets nötig, um eine robuste Transformation auf diese Weise programmieren zu können. Die Streams API abstrahiert typische Anwendungsfälle und vereinfacht die Entwicklung und das Deployment von Transformationen. KSQL ermöglicht den einfachsten Zugang zur analytischen Arbeit mit Kafka, stellt aber auch die meisten Constraints im Funktionsumfang bei größtem Overhead, schließlich ist ein weiterer Server nötig. Informatiker sollten mit dem Wissen aus dieser Ausarbeitung in der Lage sein, die Logik hinter Kafkas Producern und Consumern in Kombination mit deren Dokumentation in Code umzusetzen.
Fazit
Im Rahmen der Erstellung dieser Ausarbeitung haben sich zwei Beurteilungsebenen herauskristallisiert. Zum Ersten muss Kafka als Umsetzung einer Streaming Architektur gesehen werden. Dies war der ursprüngliche Designantrieb. Erst danach sind Tools zur Analytik hinzugekommen, die den informationszentrischen Workflow erleichtern sollten.
Kafka als Streaming Architektur
Im ersten Kapitel ist umfangreich geschildert worden, welche Probleme sich mit der Zukunft von BigData ergeben. Diese Probleme können durch die Streaming Architektur gelöst werden. Kafka greift die Idee der strömungsbasierten Infrastruktur auf und setzt sie in einem hochskalierbaren System um. Dank des Connect Frameworks ist diese neuartige Plattform auch mit Legacy- und Batch-Systemen nahtlos integrierbar. Kafka wurde zur Erstellung dieser Arbeit umfangreich getestet und es ist nachhaltig der Eindruck entstanden, dass es ein ideales System für den Eventdatenaustausch darstellt. Insbesondere Microservices können von dem Konzept profitieren. Die von ihnen emittierten Informationen sind meist als Zustandsänderung interpretierbar, also analog zu einem Event. Wird die Kommunikation eines Microservice-Applikationsverbundes mit Kafka realisiert und dabei das Prinzip des commit logs von Anfang an als treibender Aspekt des Softwaredesigns etabliert, resultiert eine beliebig horizontal skalierbare Gesamtplattform, die gegen die im ersten Kapitel geschilderten Negativeinflüsse immun zu sein scheint. Grundsätzlich lässt sich der Vorteil auf alle Einsatzzwecke übertragen, deren Kommunikationsbedürfnisse in Events übersetzbar sind, beispielsweise Function-as-a-Service oder Command-Query-Responsibility-Segregation.
Als Nachteil ist aber zu nennen, dass Kafka in seiner bei Erstellung dieses Textes aktuellen Version eine unverhältnismäßige Administrationshürde aufweist. Das fehlerfreie Deployment der Plattform war in Anbetracht der Vielzahl von beteiligten Komponenten eher entwicklerunfreundlich. Das Management der Interaktion zwischen essentiellen Modulen, wie dem Broker und der Schema Registry, gestaltete sich schwierig. Konfigurationen erfolgen grundsätzlich über eine Vielzahl von Shellskripten und REST-Schnittstellen, die entweder schlecht oder veraltet dokumentiert sind. Mit dem Confluent Control Center existiert eine kostenpflichtige Lösung, die Administration und Monitoring von ganzen Kafka Clustern erlaubt. Es wirkt allerdings befremdlich, dass der Anbieter Kafkas dessen Open-Source Bemühungen betont und dann die für einen Masseneinsatz essentiellsten Module nur unter Preisbildung auf Großkundenebene bereitstellt.
Kafka für Analytik
Nachdem Kafka einen massiven Zuspruch der Entwicklercommunity erhielt und in die Apache Foundation aufgenommen wurde, folgten nach und nach auch Erweiterungen im Bereich der Analytik. Zuerst wurde die Streams API eingebracht und danach folgte KSQL. Diese Werkzeuge sollen es ermöglichen, dass Kafka nicht nur als "Rohrsystem" unterhalb komplexer Applikationen wahrgenommen wird, sondern auch ein Informationsmehrwert aus dem Datenfluss generiert werden kann. Nach dem Test dieser Werkzeuge muss resümiert werden, dass dieses Ziel noch lange nicht erreicht scheint. Der Leistungsumfang der Streams API ist noch stark eingeschränkt gegenüber ihrer versprochenen Funktionalität. Darüber hinaus ist die API nur bei einfachsten Transformationen intuitiv. Sobald komplexere Vorhaben umgesetzt werden sollen, stellt der oft implizit formulierte Syntax eine Barriere dar. Die Entwicklung von strömungsbasierten Endlosanwendungen erfordert vom Entwickler bereits ein fundamentales Umdenken bei der Strukturierung der Software. Eine zusätzlich hinderlich formulierte API kann dann die Begeisterung für die neue Technologie schmählern. Im Falle von KSQL ist dieses Problem wunderbar gelöst. Man setzt auf den bekannten SQL-Syntax und die Arbeit mit den Datenströmen ist transparent, niederschwellig und auch in komplexen Fällen zügig. Hier liegt der große Nachteil beim zusätzlich benötigten KSQL-Server. Dieser beansprucht unüblich viele Ressourcen und ist mit gängiger Heimanwenderhardware kaum angenehm nutzbar. Allerdings muss gesagt werden, dass er bei Erstellung dieser Schrift nur in einer Previewversion vorlag und Optimierungen bis zum Release zu erwarten sind.
Neben diesen technischen Beurteilungen sollten Kafkas Analytikfähigkeiten auch im Kontext von vergleichbaren Produkten betrachtet werden. Dank Connect ist die Anbindung an Systeme, die auf Analytik und Complex-Event-Processing auf Streams spezialisiert sind, hürdenfrei möglich. Apache Samza und Apache Storm kommen aus dem gleichen Projektverbund und sind in diesem Bereich weitaus leistungsfähiger. Es scheint sinnvoll, innerhalb Kafkas die Möglichkeit zur einfachen Steuerung von Informationsflüssen und deren schnellen Manipulation zu haben, aber warum nach und nach der Fokus immer mehr Richtung komplexer Analyse verlagert wird, obwohl bereits eine Integration mit Tools existiert, die auf dem Gebiet erprobt sind, wirft Fragen auf. Hier sollte verstärkt auf Kooperation gesetzt werden, anstatt das "Rad neu zu erfinden".
Quellen
[CONF18]: Confluent. Data Serialization and Evolution. Retrieved from https://docs.confluent.io/current/avro.html. 2018. Version 4.1.1
[DUNN16]: Ted Dunning & Ellen Friedman. 2016. Streaming Architecture. New Designs Using Apache Kafka and MapR Streams. O'Reilly Media, Inc..
[KONI16a]: Konieczny, Bartosz. “Introduction to Apache ZooKeeper.” The Role of Apache ZooKeeper in Apache Kafka on Waitingforcode.com - Articles about Apache Kafka, 5 May 2016, http://www.waitingforcode.com/apache-zookeeper/introduction-to-apache-zookeeper/read.
[KONI16b]: Konieczny, Bartosz. “The role of Apache ZooKeeper in Apache Kafka.” The role of Apache ZooKeeper in Apache Kafka on Waitingforcode.com - Articles about Apache Kafka, 2 July 2016, http://www.waitingforcode.com/apache-kafka/the-role-of-apache-zookeeper-in-apache-kafka/read.
[KREP11]: Kreps, Jay, Neha Narkhede and Jun Rao. “Kafka: a Distributed Messaging System for Log Processing.” (2011).
[KREP14]: Jay Kreps. 2014. I Heart Logs. Event Data, Stream Processing, and Data Integration. O'Reilly Media, Inc..
[REIN17]: Reinsel, D., J. Gantz, and J. Rydning. "Data Age 2025: The Evolution of Data to Life-Critical. Don't Focus on Big Data; Focus on the Data That's Big." IDC, Seagate, April (2017).
[SHAP7]: Gwen Shapira, Neha Narkhede & Todd Palino. 2017. Kafka: The Definitive Guide. Real-Time Data and Stream Processing at Scale. O'Reilly Media, Inc..
[ZIKO13]: Zikopoulos, P., Deroos, D., Parasuraman, K., Deutsch, T., Corrigan, D., & Giles, J. (2013). Harness the power of big data: The IBM big data platform. New York, NY: McGraw-Hill.